Lookups are used commonly to meet different requirements. Many a times, lookup values easily go past hundred values, in such case adding the values one by one into the lookup is very tedious and error prone job.
There is no HDL support to bulk upload the lookup values. However, a file based solution is available which is easy to use and quick.
We have already discussed on how to bulk upload lookup types in below post:
Lookups – Mass Upload Lookup Types (fusionhcmconsulting.com)
Follow the below steps to mass upload lookup values:
- Create a custom lookup from UI:
[N] – Setup and Maintenance -> Search -> Manage Common Lookups
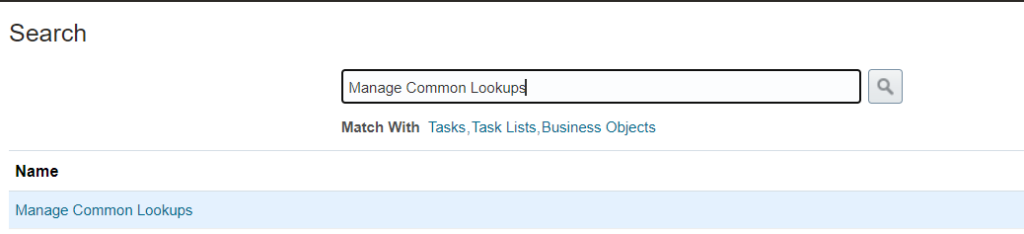
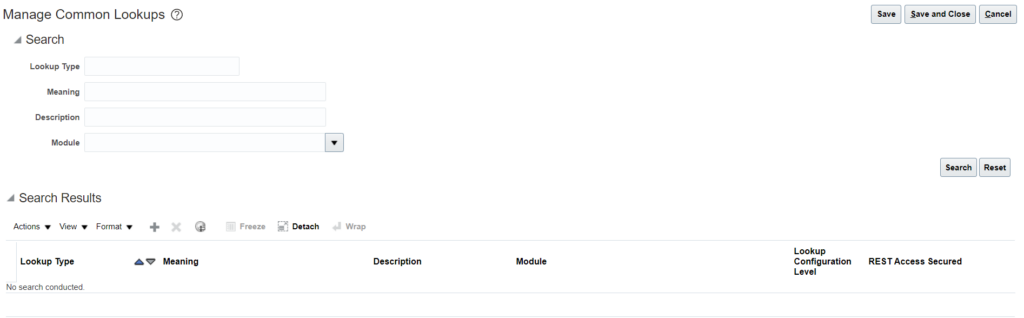
2. Click on Add New (+) under search results:
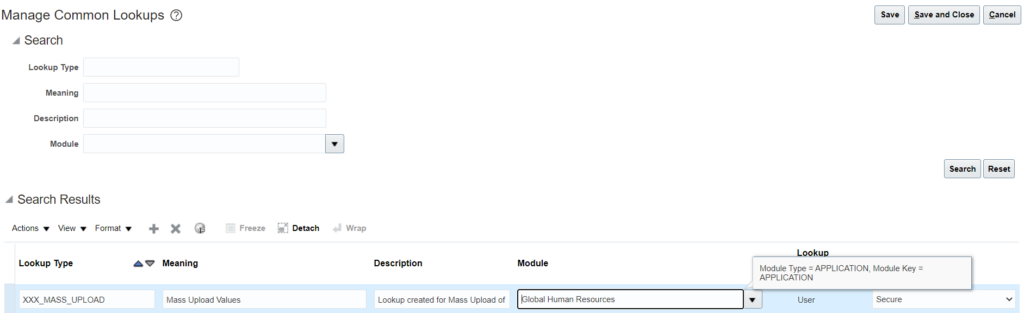
3. Provide the details and Click on Save:
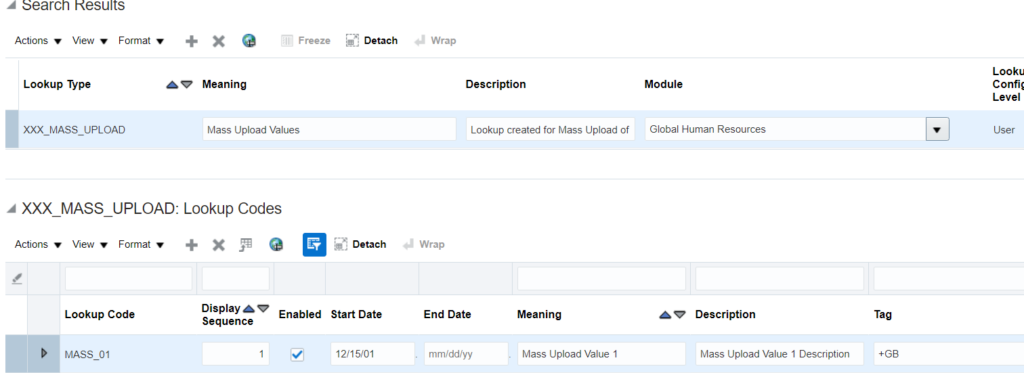
4. Prepare the lookup values file in below format:
LookupType|LookupCode|DisplaySequence|EnabledFlag|StartDateActive|EndDateActive|Meaning|Description|Tag
XXX_MASS_UPLOAD|MASS_01|1|Y|15/12/2001||Mass Upload Value 1|Mass Upload Value 1 Description|+GB
Below mentioned attributes in the above file are Mandatory:
-> LookupType
-> LookupCode
-> EnabledFlag
-> Meaning
Except these all other fields are optional.
Date Format for StartDateActive and EndDateActive attributes is DD/M/RRRR.
File should be pipe (|) delimited.
Save the file as csv.
5. Once the file is ready, navigate to – Tools -> File Import and Export
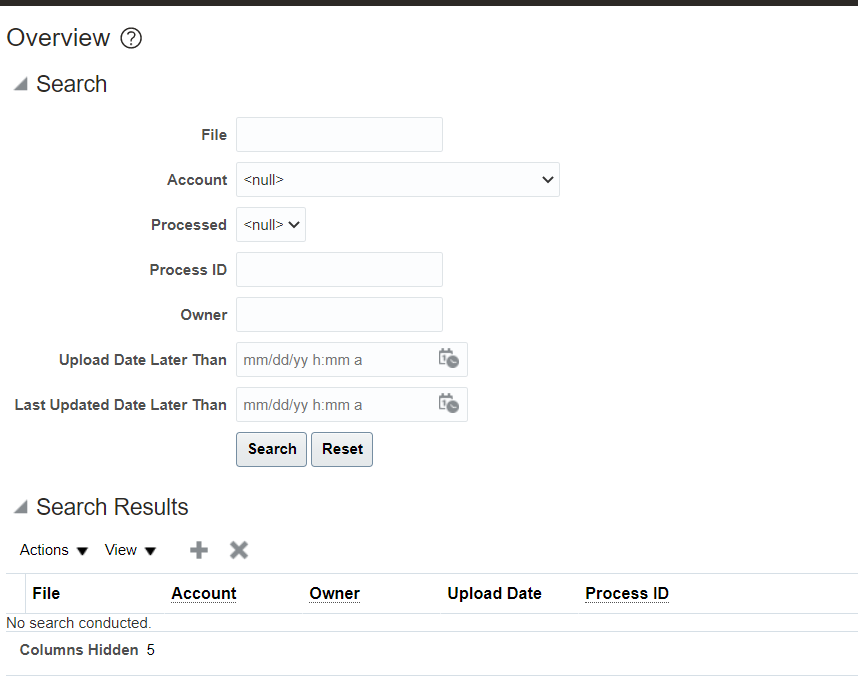
6. Click on Add (+) and choose your file:
Select account as :-> setup/functionalSetupManger/import
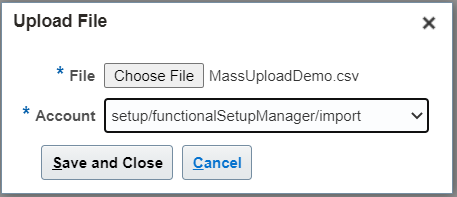
Click on Save and Close.
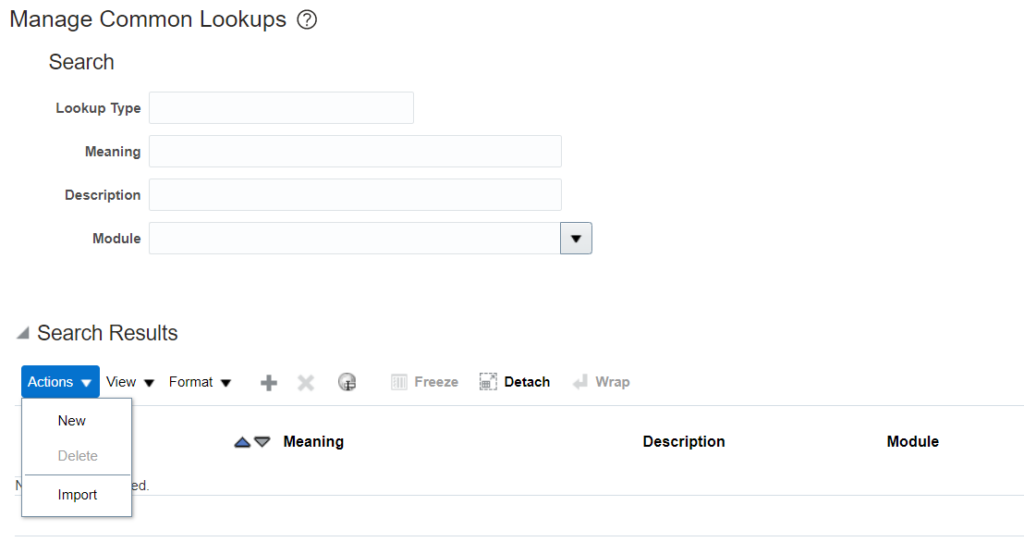
7. Navigate to Manage Common Lookups. Under Search Results click on Action and Import:
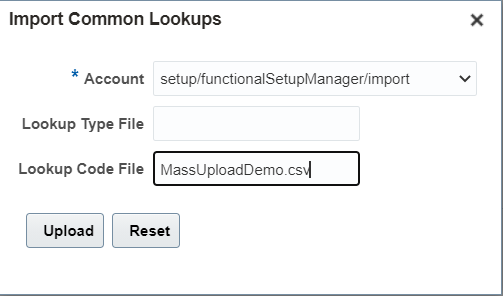
8. Select the account and give the file name as given in step 6 and Click on Upload button:
9. Monitor the import progress:
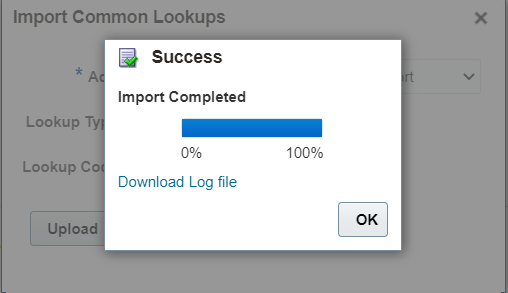
10. Once the import is complete, verify the uploaded values:
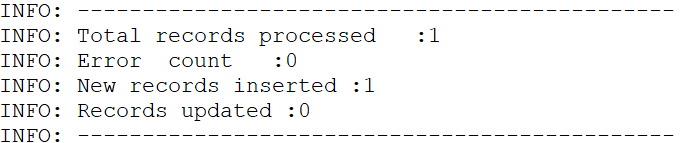
11. Results can be verified from Import file log as well:
Both Lookup types and lookup codes can be loaded in one shot as well. Prepare both the files simultaneously and follow the same steps as given above.