Once a worker is terminated in Oracle HCM Cloud, one would expect that associated User account to be inactive as well. For this to happen automatically, autoprovisioning rules should be setup which will remove the associated roles to the terminated worker’s user. In case, there is even a single role attached to the user, the user will show as active in Security Console.
From the backend, Suspended attribute in PER_USERS table is mapped to active checkbox in UI. If the user is active, the suspended flag will hold N value. For inactive users, the value of this attribute will be Y.
You can use below query to get the list of terminated workers for whom the user is still active:
SELECT papf.person_number,pu.username
FROM per_all_people_f papf
,per_all_assignments_m paam
,per_users pu
WHERE papf.person_id = paam.person_id
AND paam.effective_latest_change = 'Y'
AND paam.effective_sequence = 1
AND paam.assignment_status_type like 'INACTIVE%'
AND paam.assignment_type NOT LIKE '%T'
AND TRUNC(SYSDATE) BETWEEN papf.effective_start_date AND papf.effective_end_date
AND TRUNC(SYSDATE) BETWEEN paam.effective_start_date AND paam.effective_end_date
AND papf.person_id = pu.person_id
AND pu.suspended = 'N'
HCM Data Loader object ClassroomResource can be used to bulk upload classroom resources in Oracle Learning Cloud. Existing locations created as part of Global HR can also be designated as classroom resources.
Below is a sample file to upload classroom resources using HDL:
SELECT paam.assignment_number
,paam.labour_union_member_flag
,houft.name
FROM per_all_assignments_m paam
,hr_organization_units_f_tl houft
WHERE paam.assignment_type ='E'
AND paam.union_id = houft.organization_id
AND houft.language = 'US'
AND paam.effective_latest_change = 'Y'
AND TRUNC(SYSDATE) BETWEEN paam.effective_start_date AND paam.effective_end_date
AND TRUNC(SYSDATE) BETWEEN houft.effective_start_date AND houft.effective_end_date
select papf.person_number,
ppnf.full_name
from per_All_people_f papf
,per_person_names_f ppnf
where papf.person_id =ppnf.person_id
and ppnf.name_type= 'GLOBAL'
and trunc(sysdate) between papf.effective_start_date and papf.effective_end_date
and trunc(sysdate) between ppnf.effective_start_date and ppnf.effective_end_date
and papf.person_id = HRC_SESSION_UTIL.GET_USER_PERSONID
SELECT 'METADATA'
,'ContentItem'
,hctb.content_type_id
,hctb.context_name
,hcibt.name
,hctvt.value_set_name
,hg.geography_name
,hcibt.item_description
,to_char(hcib.date_from,'yyyy/mm/dd')
,hg.geography_code
,hcib.content_item_code
,to_char(hcib.date_to,'yyyy/mm/dd')
,hrmb.rating_model_code
,hrmb.rating_model_id
,hikm.source_system_id
,hikm.source_system_owner
FROM HRT_CONTENT_ITEMS_B hcib
,HRT_CONTENT_ITEMS_TL hcibt
,HRT_CONTENT_TYPES_B hctb
,HZ_GEOGRAPHIES hg
,HRT_RATING_MODELS_B hrmb
,HRT_CONTENT_TP_VALUESETS_TL hctvt
,HRC_INTEGRATION_KEY_MAP hikm
where hcib.CONTENT_ITEM_ID=hcibt.CONTENT_ITEM_ID
AND hcibt.LANGUAGE=userenv('LANG')
AND hcib.CONTENT_TYPE_ID=hctb.CONTENT_TYPE_ID(+)
AND hikm.surrogate_id = hcib.CONTENT_ITEM_ID
AND hcib.COUNTRY_ID=hg.GEOGRAPHY_ID(+)
AND hg.GEOGRAPHY_TYPE(+)='COUNTRY'
AND trunc(hcib.DATE_FROM) between hg.START_DATE(+) and nvl(hg.END_DATE(+),to_date('4712/12/31','YYYY/MM/DD'))
AND hcib.RATING_MODEL_ID=hrmb.RATING_MODEL_ID(+)
AND trunc(hcib.DATE_FROM) between hrmb.DATE_FROM(+) and nvl(hrmb.DATE_TO(+),to_date('4712/12/31','YYYY/MM/DD'))
AND hcib.CONTENT_VALUE_SET_ID=hctvt.CONTENT_VALUE_SET_ID(+)
AND hctvt.LANGUAGE(+)=userenv('LANG')
AND hctb.CONTEXT_NAME = 'LANGUAGE'
Goal Weightage can be updated using GoalMeasurement metadata in Goal business object. First, we need to extract the uploaded measurements. Use the below query to extract the details:
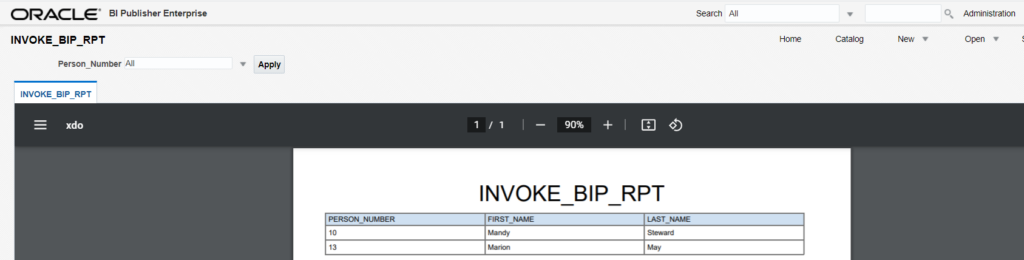
There is one common requirement where Employees should access reports directly from self-service instead of navigating to analytics. In such cases, a report link can be created and added as a static link on Navigator. This will enable the employee to access report directly. The report can be then viewed in different views using different parameters in report link.
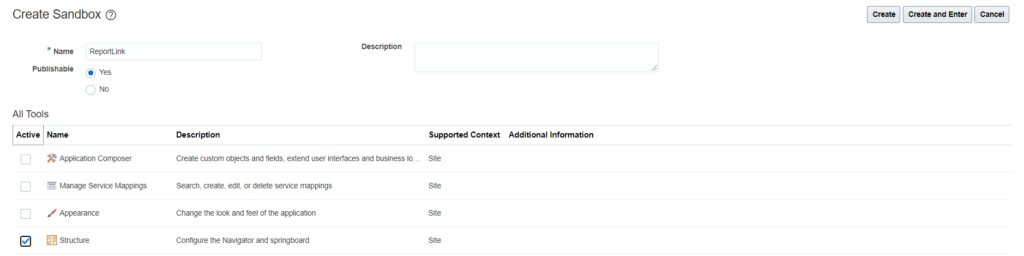
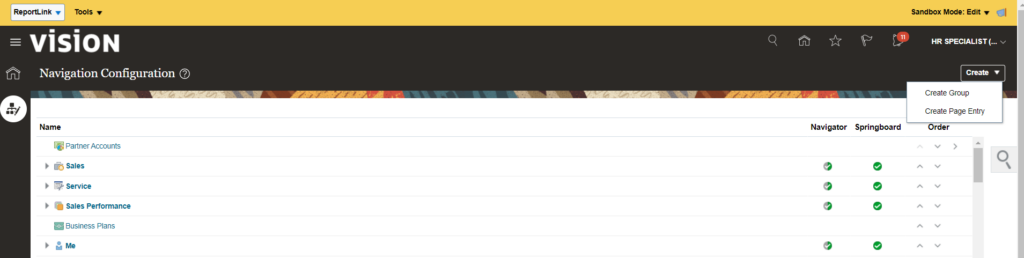
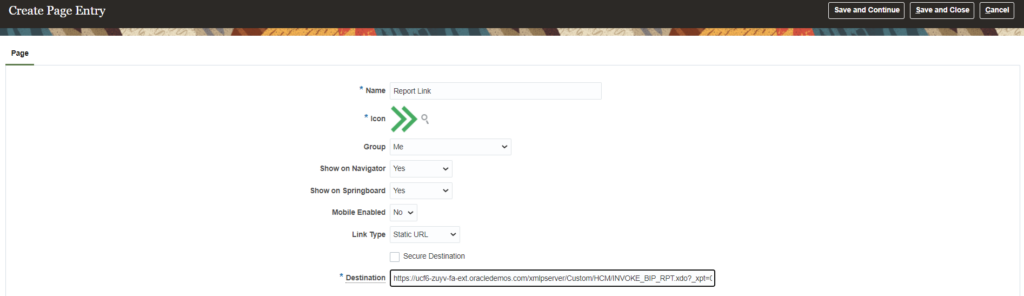
Steps to enable report link on self-service:
Derive the report link. Navigate to analytics and open the report:
Each person can publish public info in HCM Cloud by navigating to Me -> Quick Actions -> Public Info. There are various sections under Public Info like Public Message, Contact Info, About Me etc.
You can use the below SQL queries to extract the data for relevant sections.
Public Message:
SQL Query:
SELECT papf.person_number
,ppnf.full_name
,ppmv.PORTRAIT_MESSAGE_CONTENT
,ppmv.TIME_FROM
,ppmv.TIME_TO
FROM per_all_people_f papf
,per_person_names_f ppnf
,per_portrait_messages_vl ppmv
WHERE papf.person_id = ppnf.person_id
AND ppnf.name_type = 'GLOBAL'
AND papf.person_id = ppmv.target_person_id
AND TRUNC(SYSDATE) BETWEEN papf.effective_start_date AND papf.effective_end_date
AND TRUNC(SYSDATE) BETWEEN ppnf.effective_start_date AND ppnf.effective_end_date
About Me:
SQL Query:
select papf.person_number
,ppnf.full_name
,hpv.summary about_me
,hpkaoe.keywords area_of_expertise
,regexp_replace(regexp_replace(regexp_replace(hpkaoe.KEYWORDS, '</p><br/>'), '</p>'),'<p>') as Area_Of_Expert
ise_wo_html
,hpkaoi.keywords area_of_interest
,regexp_replace(regexp_replace(regexp_replace(hpkaoi.KEYWORDS, '</p><br/>'), '</p>'),'<p>') as area_of_interest_wo_html
from PER_ALL_PEOPLE_F papf,
PER_PERSON_NAMES_F ppnf,
HRT_PROFILES_VL hpv,
HRT_PROFILE_KEYWORDS hpkaoe,
HRT_PROFILE_KEYWORDS hpkaoi
where hpv.profile_id = hpkaoe.profile_id
and hpkaoe.profile_id = hpkaoi.profile_id
and hpkaoe.keyword_type = 'AOE'
and hpkaoi. keyword_type = 'AOI'
and papf.person_id = hpv.person_id
and papf.person_id = ppnf.person_id
and ppnf.name_type = 'GLOBAL'
and TRUNC(SYSDATE) BETWEEN papf.effective_start_date AND papf.effective_end_date
and TRUNC(SYSDATE) BETWEEN ppnf.effective_start_date AND ppnf.effective_end_date
There are multiple objects in Oracle HCM Cloud which support attachments. Often, there is a need to extract the attachment details stored at the object level. All the uploaded attachments are stored in fnd_attached_documents table. Below query is used to extract the attachment details stored at Service Request level in HR Helpdesk. You can replace the table name and primary key join to extract the data as per your requirement:
select ssr.sr_id,
ssr.title,
fad.CATEGORY_NAME ,
fdt.file_name,
fdt.dm_version_number document_id,
fdt.dm_document_id UCM_file
from fnd_attached_documents fad, svc_service_requests ssr, fnd_documents_tl fdt
where ENTITY_NAME = 'SVC_SERVICE_REQUESTS'
and ssr.sr_id = fad.PK1_VALUE
and fad.document_id = fdt.document_id
and fdt.language = 'US'
Query to get list of Jobs having an attachment:
select pjft.name
from per_jobs_f_tl pjft
where pjft.language = 'US'
and exists (select 1
from fnd_attached_documents fad, PER_JOBS_F pjf, fnd_documents_tl fdt
where ENTITY_NAME = 'PER_JOBS_F'
and pjf.job_id = fad.PK1_VALUE
and fad.document_id = fdt.document_id
and fdt.language = 'US'
and pjf.job_id = pjft.job_id)
Refer below link for attachments on Position profile:
In order to download the attchments from UCM, the user should have AttachmentsRead role attached. Please check the below post on how to create AttachmentsRead role:
Employee category (EMPLOYEE_CATG) is a delivered user type lookup in Oracle HCM which can be extended. However, in few cases, there is a requirement to populate employee category at DFF attribute(s), in this case, we need to create a table defined value set.
FROM Clause
fnd_lookup_values
Value Attributes Table Alias
*Value Column Name
substr(meaning,1,80)
Value Column Type
VARCHAR2
Value Column Length
80
Description Column Name
substr(meaning,1,100)
Description Column Type
VARCHAR2
Description Column Length
80
ID Column Name
substr(meaning,1,100)
ID Column Type
VARCHAR2
ID Column Length
80
Enabled Flag Column Name
Start Date Column Name
End Date Column Name
WHERE Clause
lookup_type= ‘EMPLOYEE_CATG’ and TAG is NULL and language = ‘US’ and enabled_flag = ‘Y’
SELECT hapft.name
,pcaa.segment1
,pcaa.segment2
,pcaa.segment3
,pcaa.segment4
,pcaa.segment5
,pcaa.segment6
,pcaa.segment7
,pcaa.segment8
FROM PAY_COST_ALLOCATIONS_F pacf
,PAY_COST_ALLOC_ACCOUNTS pcaa
,HR_ALL_POSITIONS_F hapf
,HR_ALL_POSITIONS_F_TL hapft
WHERE pacf.cost_allocation_record_id = pcaa.cost_allocation_record_id
AND pacf.source_type = 'POS'
AND pacf.source_id = hapf.position_id
AND hapft.position_id = hapf.position_id
AND hapft.language = 'US'
AND TRUNC(SYSDATE) BETWEEN pacf.effective_start_date AND pacf.effective_end_date
AND TRUNC(SYSDATE) BETWEEN hapf.effective_start_date AND hapf.effective_end_date
AND TRUNC(SYSDATE) BETWEEN hapft.effective_start_date AND hapft.effective_end_date
Often in Cloud HCM, we encounter situation(s) where we need to update some information at worker assignment, post worker creation as this information was not available at the time of hiring an worker. One such example could be Employee category. Let’s take a hypothetical example, employee category should be auto populated based on worker Job. As, there is no direct link between employee category and job, so it becomes a pain to manually search and put the correct employee category while hiring. So, in this case, the worker is hired with Job with no value for employee category.
A DFF is opened at Job level which store the corresponding employee category. So, in this case we design a solution which will:
Read the worker job and then the corresponding employee category from Job.
Generate the data for WorkTerms and Assignments METADATA in HCM Data Loader Format.
HCM Extract to consume the data and trigger HDL Import and Load Process.
Schedule HCM Extract to run daily or depending upon the requirement.
Once, HCM Extract is run, employee category will populated automatically.
Steps to design the integration:
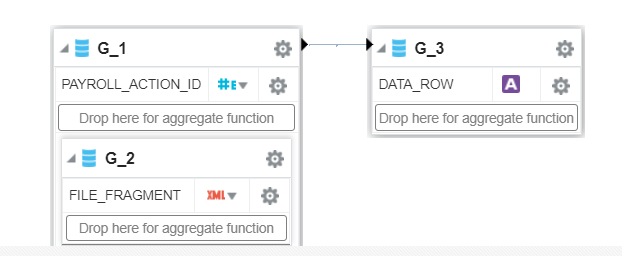
Extract the Workterms and assignment data for all workers where the job is populated and employee category is NULL.
Create a BIP publisher report to organize the data extracted in Step 1 in HCM Data Loader format. Copy the Global Reports Data Model (from path /Shared Folders/Human Capital Management/Payroll/Data Models/globalReportsDataModel) to a folder in /Shared Folders/Custom/HR. This folder can be anything as per your nomenclature specifications.
Add a new data set in the globalReportsDataModel and paste your query in the new data set.
Download the above file. Change the extension to xml.
Open the xml file with Notepad or Notepad++ and remove first two rows (these rows were added to make sure the file is uploaded here).
Navigate to My Client Groups -> Data Exchange -> HCM Extracts -> Extract Definitions:
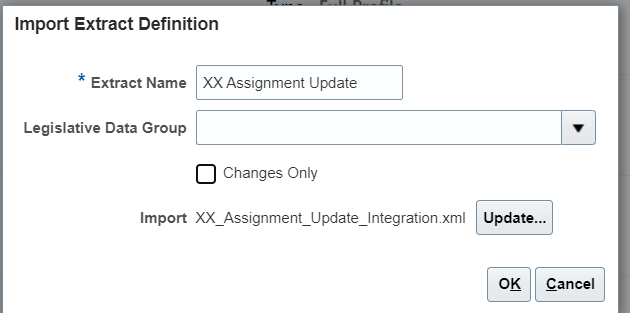
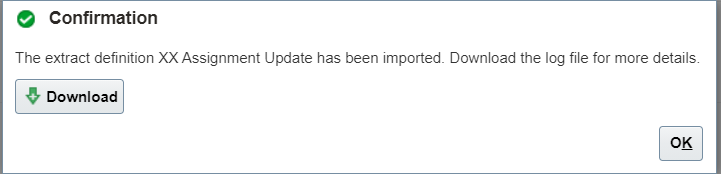
Click on Import to import the xml file
Provide an Extract name. Uncheck the Changes Only checkbox and click on Ok:
Once the extract Import is complete, Click on pencil icon to edit:
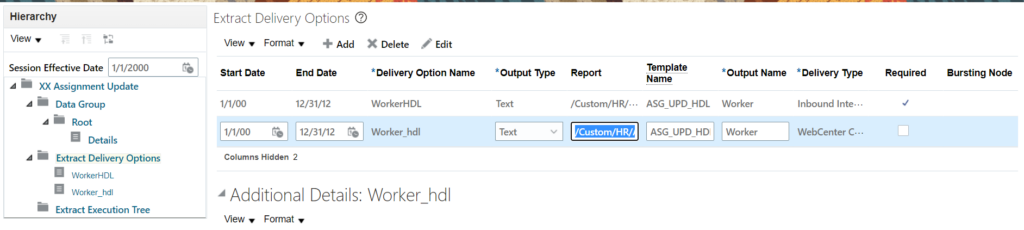
Click on ‘Extract Delivery Option’ in navigation Tree on left side. And on the right side, Under ‘Extract Delivery Options’ click on edit to update the path of your report as created earlier. It should like – /Custom/HR/AssignmentUpdateRPT.xdo
Make sure default value for parameter Auto Load is set “Y”.
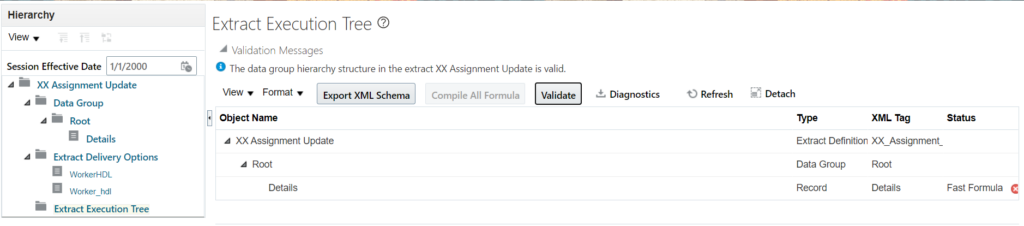
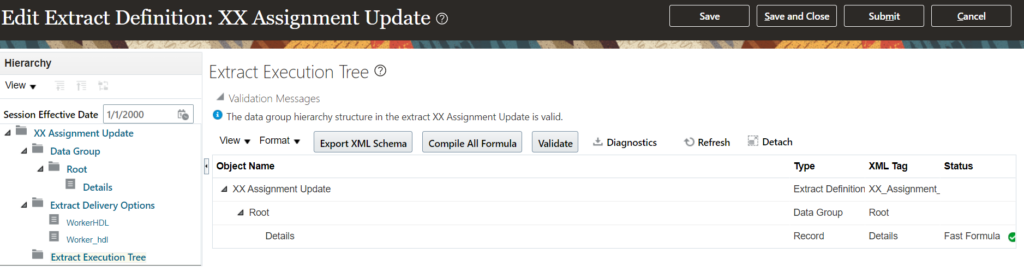
Save the details. Click on Extract Execution Tree next and Click All Formula:
Once the formulas are complied, then click on Submit button.
The next step is to refine the extract in order to Submit the Import and Load process:
Navigate to My Client Groups -> Data Exchange -> HCM Extracts -> Refine Extracts. Search the extract and click on edit.
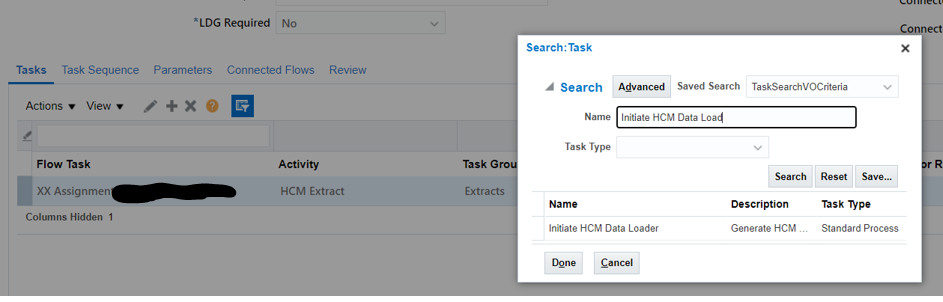
Select and Add – Initiate HCM Data Loader process
Click on Go Task for “Initiate HCM Data Loader” and Click Edit for “ Data Loader Archive Action” and add the relevant parameters:
Parameter Basis – Bind to Flow Task Basis Value – XX Assignment Update Integration, Submit , Payroll Process
Click Edit for “Data Loader Configurations” add relevant parameters
Parameter Basis – Constant Bind Basis Value -ImportMaximumErrors=100,LoadMaximumErrors=100,LoadConcurrentThreads=8,LoadGroupSize=100
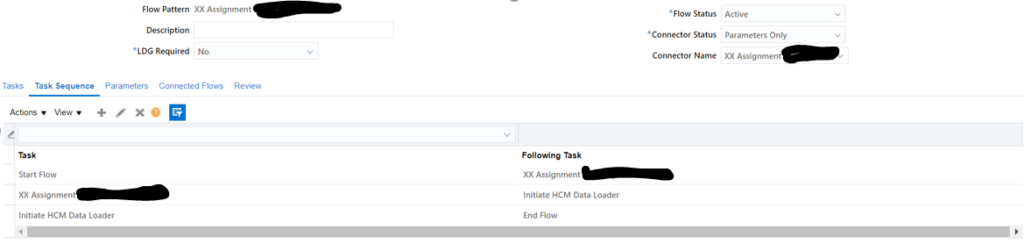
Task sequence should look as follows:
Go to Review and click on Submit.
Your extract is now ready for submission. You can submit the extract and test it.
When position hierarchy is enabled in Cloud HCM, Manage Positions UI shows some dynamically populated fields along with Parent position.
For example:
Use the below query to extract above details:
SELECT Positions.name "Position Name"
,Positions.FTE "Position Current FTE"
,Positions.INCUMBENT_FTE "Current Incumbent FTE"
,(Positions.FTE - Positions.INCUMBENT_FTE) "Difference FTE"
FROM
(SELECT HAPFT.NAME,
HAPF.FTE,
(select SUM(PAWMF.VALUE)
from PER_ALL_ASSIGNMENTS_M PAAM,
PER_ASSIGN_WORK_MEASURES_F PAWMF
where 1=1
AND PAAM.POSITION_ID = HAPF.POSITION_ID
AND SYSDATE BETWEEN PAAM.EFFECTIVE_START_DATE AND PAAM.EFFECTIVE_END_DATE
AND PAAM.ASSIGNMENT_TYPE = 'E'
AND PAAM.ASSIGNMENT_STATUS_TYPE = 'ACTIVE'
AND PAAM.ASSIGNMENT_ID = PAWMF.ASSIGNMENT_ID
AND PAWMF.UNIT = 'FTE') AS INCUMBENT_FTE
FROM HR_ALL_POSITIONS_F HAPF,
HR_ALL_POSITIONS_F_TL HAPFT
WHERE HAPF.POSITION_ID = HAPFT.POSITION_ID
AND USERENV('LANG') = HAPFT.LANGUAGE
AND TRUNC(SYSDATE) BETWEEN HAPF.EFFECTIVE_START_DATE AND HAPF.EFFECTIVE_END_DATE
AND TRUNC(SYSDATE) BETWEEN HAPFT.EFFECTIVE_START_DATE AND HAPFT.EFFECTIVE_END_DATE
AND HAPFT.NAME IN('Test Position')
ORDER BY HAPFT.NAME ) Positions
Below query will extract all the custom fast formulas along with the name of formula and formula type.
select fff.formula_name
,fft.formula_type_name
,fff.formula_text
,fff.compile_flag
,fff.legislation_code
from ff_formulas_f fff
,ff_formula_types fft
where fff.formula_type_id = fft.formula_type_id
--and fft.formula_type_name = 'Extract Criteria'
and fff.LAST_UPDATED_BY <> 'SEED_DATA_FROM_APPLICATION'
AND TRUNC(SYSDATE) BETWEEN fff.effective_start_date AND fff.effective_end_date
ORDER BY 2,1
To extract list of fast formulas used in HCM Extracts, run below query:
SELECT pedv.definition_name
,pedv.description
,pedv.legislation_code
,pedv.xml_tag_name
,pedv.ext_type_code
,fff.formula_name
,fft.formula_type_name
FROM pay_rep_criteria_f prcf
,pay_report_blocks_vl prbv
,per_ext_definitions_vl pedv
,ff_formulas_f fff
,ff_formula_types fft
WHERE prbv.ext_definition_id = pedv.ext_definition_id
AND prcf.report_block_id = prbv.report_block_id
AND fff.formula_id = prcf.formula_id
AND TRUNC(SYSDATE) BETWEEN fff.effective_start_date AND fff.effective_end_date
AND TRUNC(SYSDATE) BETWEEN prcf.effective_start_date AND prcf.effective_end_date
AND fff.formula_type_id = fft.formula_type_id
Actions and Action Reasons are very important part of any Cloud HCM implementation. Oracle provides a large number of actions and action reasons out of the box. But if needed additional actions and action reasons can be created from UI as well as using HDL.
Each action is tied with an action type. Please note that action types are seeded and can’t be created. You can create a custom action and attach existing action reasons to it. The details are stored in PER_ACTION_REASON_USAGES table.
During implementation, there is a common requirement to delete some of the unwanted action reason usages which were created initially and are no longer required. In such cases finding each reason and deleting it from action is quite a painful task.
This can be achieved easily using HCM Data Loader.
Run the below query in BIP and save the file as Actions.dat. Zip the file and kick Import and Load HCM Data Loader process. You can modify the extract criteria as per your requirement:
SELECT data
FROM (
SELECT 'METADATA|ActionReasonUsage|ActionCode|ActionReasonCode|StartDate|EndDate|SourceSystemId|SourceSystemOwner' data, 1 DATA_SEQ
FROm DUAL
UNION ALL
Select 'DELETE|ActionReasonUsage|'
||
paru.action_code
||'|'||
paru.action_reason_code
||'|'||
to_char(paru.start_date, 'yyyy/mm/dd')
||'|'||
to_char(paru.end_date, 'yyyy/mm/dd')
||'|'||
hikm.source_system_id
||'|'||
hikm.source_system_owner data, 2 DATA_SEQ
from
hrc_integration_key_map hikm,
PER_ACTION_REASON_USAGES paru
where 1=1
and paru.ACTION_REASON_USAGE_ID = hikm.surrogate_id
and paru.created_by <> 'SEED_DATA_FROM_APPLICATION'
)
ORDER BY DATA_SEQ
While extending the DFF attributes for additional functionality, one of the common requirements is to get the list of workers in the system.
For this purpose a table based value set can be defined and attached to the DFF attribute.
FROM Clause
per_all_people_f papf, per_person_names_f ppnf
Value Attributes Table Alias
*Value Column Name
papf.person_number
Value Column Type
VARCHAR2
Value Column Length
30
Description Column Name
ppnf.full_name
Description Column Type
Description Column Length
ID Column Name
papf.person_number
ID Column Type
VARCHAR2
ID Column Length
30
Enabled Flag Column Name
Start Date Column Name
End Date Column Name
WHERE Clause
trunc(SYSDATE) between papf.effective_start_date AND papf.effective_end_date AND trunc(SYSDATE) between ppnf.effective_start_date AND ppnf.effective_end_date and ppnf.name_type = ‘GLOBAL’ and ppnf.person_id=papf.person_id and papf.person_id IN (select distinct person_id from per_periods_of_Service ppos where NVL(ppos.actual_termination_date, trunc(sysdate)) >= trunc(sysdate))
ORDER BY Clause
The above value set will show a list of only active employees. If you want to include inactive employees as well, please modify the where clause as below:
trunc(SYSDATE) between papf.effective_start_date AND papf.effective_end_date
AND trunc(SYSDATE) between ppnf.effective_start_date AND ppnf.effective_end_date
and ppnf.name_type = 'GLOBAL'
and ppnf.person_id=papf.person_id
and papf.person_id IN (select distinct person_id from per_periods_of_Service ppos)
select hauft.NAME
from HR_ORG_UNIT_CLASSIFICATIONS_F houcf,
HR_ALL_ORGANIZATION_UNITS_F haouf,
HR_ORGANIZATION_UNITS_F_TL hauft
where haouf.ORGANIZATION_ID = houcf.ORGANIZATION_ID
AND haouf.ORGANIZATION_ID = hauft.ORGANIZATION_ID
AND haouf.EFFECTIVE_START_DATE BETWEEN houcf.EFFECTIVE_START_DATE AND houcf.EFFECTIVE_END_DATE
AND hauft.LANGUAGE = 'US'
AND hauft.EFFECTIVE_START_DATE = haouf.EFFECTIVE_START_DATE
AND hauft.EFFECTIVE_END_DATE = haouf.EFFECTIVE_END_DATE
AND houcf.CLASSIFICATION_CODE = 'FUN_BUSINESS_UNIT'
AND trunc(SYSDATE) BETWEEN hauft.effective_start_date AND hauft.effective_end_date