Use below query to extract files loaded through Tools -> File Import and Export along with UCM Content ID and the account used:
SELECT DDOCTITLE "File Name"
,DWEBEXTENSION "File Extension"
,DDOCACCOUNT "Account"
,DDOCAUTHOR "Owner"
,DINDATE "Upload Date"
,DDOCNAME "Content Id"
,DDOCTYPE "Doc Type"
FROM revisions
WHERE DWEBEXTENSION <> 'log'
AND DDOCTITLE NOT LIKE 'ESS%'
ORDER BY DCREATEDATE DESC
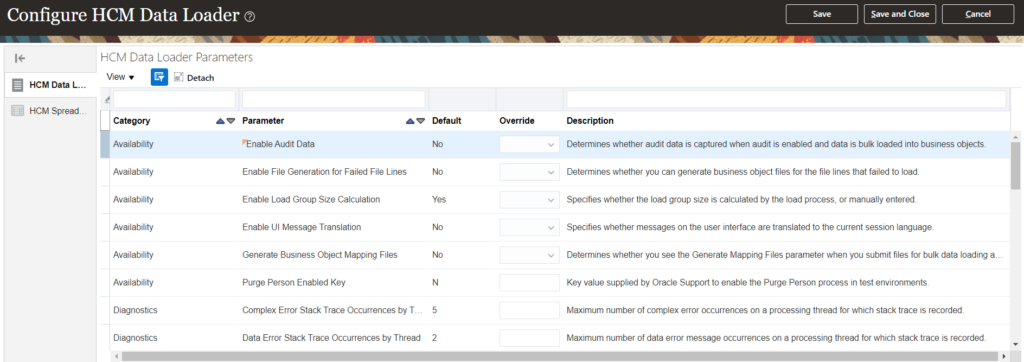
Configure HCM Data Loader is a task that is used to define the HCM Data Loader parameters. The parameters are broadly divided into following categories:- Availability, Diagnostic, File Definition, Performance and Scheduling Default. These are the default settings which are applied to any HCM Data Load.
You can override some of these parameters at the individual dat file level i.e. using SET commands or some of the parameters can be overridden while submitting the Import and Load job.
Please note that the default values vary from HDL to HSDL (Spreadsheet Loader).
You can use below mentioned query to get the details from backend using a BIP:
select PARAM_CATEGORY
,PARAM_NAME
,DEFAULT_VALUE
,HSDL_DEFAULT_VALUE
,HDL_ENABLED
,HDL_OVERRIDE_ENABLED
,HSDL_ENABLED
,HSDL_OVERRIDE_ENABLED
,VALUE_LOOKUP_TYPE
,CREATED_BY
,CREATION_DATE
,LAST_UPDATED_BY
,LAST_UPDATE_DATE
from hrc_dl_all_parameters
ORDER By 1,2
Query to get list of overridden values:
select hdap.PARAM_CATEGORY
,hdap.PARAM_NAME
,hdap.DEFAULT_VALUE
,hdap.HSDL_DEFAULT_VALUE
,hdap.HDL_ENABLED
,hdap.HDL_OVERRIDE_ENABLED
,hdap.HSDL_ENABLED
,hdap.HSDL_OVERRIDE_ENABLED
,hdap.VALUE_LOOKUP_TYPE
,hdap.CREATED_BY
,hdap.CREATION_DATE
,hdap.LAST_UPDATED_BY
,hdap.LAST_UPDATE_DATE
,hdpo.OVERRIDE_LEVEL "OVERRIDDEN_AT_LEVEL"
,hdpo.OVERRIDE_VALUE "OVERRIDDEN_VALUE"
from hrc_dl_all_parameters hdap
,hrc_dl_parameter_overrides hdpo
where hdap.parameter_id = hdpo.parameter_id
ORDER By 1,2
In Oracle Learning Cloud, a specialization can be created as a combination of multiple sections with each section comprising of multiple courses.
A learning admin can setup the specialization by navigating to My Client Groups -> Learning -> Learning Catalog -> Specializations:
Example:
Use the below query to get the above details:
WITH specialization as
(SELECT
LearningItemDEO.LEARNING_ITEM_ID,
LearningItemDEO.EFFECTIVE_START_DATE SPESD,
LearningItemDEO.EFFECTIVE_END_DATE SPEED,
LearningItemDEO.LEARNING_ITEM_TYPE SPLIT,
LearningItemDEO.LEARNING_ITEM_SUB_TYPE SPLIST,
LearningItemDEO.LEARNING_ITEM_NUMBER,
LearningItemDEO.STATUS SP_STATUS,
LearningItemDEO.START_DATE SPSD,
LearningItemDEO.END_DATE SPED,
to_date(TO_CHAR( LearningItemDEO.CREATION_DATE,'MM/DD/YYYY'),'MM/DD/YYYY') AS SPCreationDate,
LearningItemTranslationDEO.NAME,
LearningItemDEO.LI_START_DATE as SP_LiStartDate,
LearningItemDEO.LI_END_DATE as SP_LiEndDate
FROM WLF_LEARNING_ITEMS_F LearningItemDEO,
WLF_LEARNING_ITEMS_F_TL LearningItemTranslationDEO
WHERE LearningItemDEO.LEARNING_ITEM_TYPE IN ('ORA_SPECIALIZATION')
AND LearningItemDEO.LEARNING_ITEM_ID = LearningItemTranslationDEO.LEARNING_ITEM_ID
AND TRUNC(SYSDATE) BETWEEN LearningItemTranslationDEO.EFFECTIVE_START_DATE AND LearningItemTranslationDEO.EFFECTIVE_END_DATE
AND TRUNC(SYSDATE) BETWEEN LearningItemDEO.EFFECTIVE_START_DATE AND LearningItemDEO.EFFECTIVE_END_DATE
AND LearningItemTranslationDEO.LANGUAGE = USERENV('lang')
--AND LearningItemTranslationDEO.NAME LIKE ('Working From Home Guidelines and Tips')
)
, Section as
(SELECT
LearningItemDEO.LEARNING_ITEM_ID,
LearningItemDEO.EFFECTIVE_START_DATE,
LearningItemDEO.EFFECTIVE_END_DATE,
LearningItemDEO.LEARNING_ITEM_TYPE,
LearningItemDEO.LEARNING_ITEM_SUB_TYPE,
LearningItemDEO.LEARNING_ITEM_NUMBER,
LearningItemDEO.STATUS,
LearningItemDEO.START_DATE,
LearningItemDEO.END_DATE,
to_date(TO_CHAR( LearningItemDEO.CREATION_DATE,'MM/DD/YYYY'),'MM/DD/YYYY') AS LearningItemDEOCreationDate,
LearningItemTranslationDEO.NAME,
LearningItemTranslationDEO.DESCRIPTION,
LearningItemDEO.LI_START_DATE as LearningItemDEOLiStartDate,
LearningItemDEO.LI_END_DATE as LearningItemDEOLiEndDate
FROM WLF_LEARNING_ITEMS_F LearningItemDEO,
WLF_LEARNING_ITEMS_F_TL LearningItemTranslationDEO
WHERE LearningItemDEO.LEARNING_ITEM_TYPE IN ('ORA_SPECL_SECTION')
AND LearningItemDEO.LEARNING_ITEM_ID = LearningItemTranslationDEO.LEARNING_ITEM_ID
AND TRUNC(SYSDATE) BETWEEN LearningItemTranslationDEO.EFFECTIVE_START_DATE AND LearningItemTranslationDEO.EFFECTIVE_END_DATE
AND TRUNC(SYSDATE) BETWEEN LearningItemDEO.EFFECTIVE_START_DATE AND LearningItemDEO.EFFECTIVE_END_DATE
AND LearningItemTranslationDEO.LANGUAGE = USERENV('lang')
)
, course as
(
SELECT
LearningItemDEO.LEARNING_ITEM_ID,
LearningItemDEO.EFFECTIVE_START_DATE,
LearningItemDEO.EFFECTIVE_END_DATE,
LearningItemDEO.LEARNING_ITEM_TYPE,
LearningItemDEO.LEARNING_ITEM_SUB_TYPE,
LearningItemDEO.LEARNING_ITEM_NUMBER,
LearningItemDEO.STATUS,
to_date(TO_CHAR( LearningItemDEO.CREATION_DATE,'MM/DD/YYYY'),'MM/DD/YYYY') AS LearningItemDEOCreationDate,
LearningItemTranslationDEO.NAME,
LearningItemTranslationDEO.DESCRIPTION,
LearningItemDEO.LI_START_DATE as LearningItemDEOLiStartDate,
LearningItemDEO.LI_END_DATE as LearningItemDEOLiEndDate
FROM WLF_LEARNING_ITEMS_F LearningItemDEO,
WLF_LEARNING_ITEMS_F_TL LearningItemTranslationDEO
WHERE LearningItemDEO.LEARNING_ITEM_TYPE IN ('ORA_COURSE')
AND LearningItemDEO.LEARNING_ITEM_ID = LearningItemTranslationDEO.LEARNING_ITEM_ID
AND TRUNC(SYSDATE) BETWEEN LearningItemTranslationDEO.EFFECTIVE_START_DATE AND LearningItemTranslationDEO.EFFECTIVE_END_DATE
AND TRUNC(SYSDATE) BETWEEN LearningItemDEO.EFFECTIVE_START_DATE AND LearningItemDEO.EFFECTIVE_END_DATE
AND LearningItemTranslationDEO.LANGUAGE = USERENV('lang')
)
, offering as
(
select WLFI.LEARNING_ITEM_NUMBER
,TO_CHAR(WLFI.EFFECTIVE_END_DATE,'YYYY/MM/DD')
,TO_CHAR(WLFI.EFFECTIVE_START_DATE,'YYYY/MM/DD')
,WLFT.DESCRIPTION
,WLFT.DESCRIPTION_LONG
,WLCF.ENABLE_CAPACITY
,WLCF.ENABLE_WAITLIST
,WLFI.LANGUAGE_CODE
,WLFI.STATUS
,WLCLF.MAXIMUM_ATTENDEES
,WLCLF.MINIMUM_ATTENDEES
,TO_CHAR(WLCLF.ENROLMENT_END_DATE,'YYYY/MM/DD')
,TO_CHAR(WLCLF.ENROLMENT_START_DATE,'YYYY/MM/DD')
,WLCLF.DELIVERY_MODE
,TO_CHAR(WLFI.END_DATE,'YYYY/MM/DD')
,TO_CHAR(WLFI.START_DATE,'YYYY/MM/DD')
,WLFT.NAME
,WLCF.LEARNING_ITEM_ID WLCF_LEARNING_ITEM_ID
FROM WLF_LEARNING_ITEMS_F WLFI,
WLF_LI_COURSES_F WLCF, --LEARNING_ITEM_ID course
WLF_LI_CLASSES_F WLCLF,
WLF_LEARNING_ITEMS_F_TL WLFT
WHERE WLFI.LEARNING_ITEM_ID = WLFT.LEARNING_ITEM_ID
AND WLFI.LEARNING_ITEM_ID = WLCLF.LEARNING_ITEM_ID
AND WLCLF.COURSE_LEARNING_ITEM_ID = WLCF.LEARNING_ITEM_ID
AND WLFT.LANGUAGE = USERENV('lang')
AND TRUNC(SYSDATE) BETWEEN WLFI.EFFECTIVE_START_DATE AND WLFI.EFFECTIVE_END_DATE
AND TRUNC(SYSDATE) BETWEEN WLCF.EFFECTIVE_START_DATE AND WLCF.EFFECTIVE_END_DATE
AND TRUNC(SYSDATE) BETWEEN WLCLF.EFFECTIVE_START_DATE AND WLCLF.EFFECTIVE_END_DATE
AND TRUNC(SYSDATE) BETWEEN WLFT.EFFECTIVE_START_DATE AND WLFT.EFFECTIVE_END_DATE
AND WLFI.LEARNING_ITEM_TYPE = 'ORA_CLASS'
)
SELECT specialization.name "Specialization Name"
,specialization.LEARNING_ITEM_NUMBER "Specialization Number"
,Section.name "Section Name"
,Section.LEARNING_ITEM_NUMBER "Section Number"
,WLF_LI_HIERARCHIES_F_SS.position "Section Position"
,course.name "Course Name"
,course.learning_item_number "Course Number"
,WLF_LI_HIERARCHIES_F_SC.HIERARCHY_NUMBER "Activity Number"
,WLF_LI_HIERARCHIES_F_SC.position "Course Position"
,offering.name "Offering Name"
,offering.LEARNING_ITEM_NUMBER "Offering Number"
,offering.DELIVERY_MODE "Offering Delivery Mode"
,offering.STATUS "Offering Status"
FROM WLF_LI_HIERARCHIES_F WLF_LI_HIERARCHIES_F_SS,
WLF_LI_HIERARCHIES_F WLF_LI_HIERARCHIES_F_SC,
specialization,
section,
course,
offering
WHERE specialization.name = 'Essential Worker'
AND WLF_LI_HIERARCHIES_F_SS.LEARNING_ITEM_ID = specialization.LEARNING_ITEM_ID
AND WLF_LI_HIERARCHIES_F_SS.CHILD_LEARNING_ITEM_ID = section.LEARNING_ITEM_ID
AND TRUNC(SYSDATE) BETWEEN WLF_LI_HIERARCHIES_F_SS.EFFECTIVE_START_DATE AND WLF_LI_HIERARCHIES_F_SS.EFFECTIVE_END_DATE
AND WLF_LI_HIERARCHIES_F_SC.LEARNING_ITEM_ID = section.LEARNING_ITEM_ID
AND WLF_LI_HIERARCHIES_F_SC.CHILD_LEARNING_ITEM_ID = course.LEARNING_ITEM_ID
AND TRUNC(SYSDATE) BETWEEN WLF_LI_HIERARCHIES_F_SC.EFFECTIVE_START_DATE AND WLF_LI_HIERARCHIES_F_SC.EFFECTIVE_END_DATE
AND course.LEARNING_ITEM_ID = offering.WLCF_LEARNING_ITEM_ID
ORDER BY specialization.name,WLF_LI_HIERARCHIES_F_SS.position,WLF_LI_HIERARCHIES_F_SC.position
Select DISTINCT peevf.element_entry_value_id
,peef.element_entry_id
,petf.base_element_name
,peevf.effective_start_date
,paam.assignment_number
,pivf.base_name
from per_all_assignments_m paam
,pay_element_types_f petf
,pay_element_entries_f peef
,pay_element_entry_values_f peevf
,pay_input_values_f pivf
where 1=1
and paam.person_id = peef.person_id
and peef.element_type_id = petf.element_type_id
and pivf.element_type_id = petf.element_type_id
and peef.element_entry_id = peevf.element_entry_id
and paam.ASSIGNMENT_TYPE in ('E')
and paam.primary_assignment_flag = 'Y'
and petf.base_element_name = 'Dental Plan'
and pivf.base_name = 'Amount'
and paam.assignment_number = 'E1111'
and trunc(sysdate) between petf.effective_start_date and petf.effective_end_date
and trunc(sysdate) between paam.effective_start_date and paam.effective_end_date
and trunc(sysdate) between pivf.effective_start_date and pivf.effective_end_date
select hapf.position_code
,hpb.profile_code
,hpt.description profile_desc
,hpt.summary
,hpeiv.DESCRIPTION
,hpeiv.RESPONSIBILITIES
,hpeiv.QUALIFICATIONS
from HRT_PROFILE_ITEMS hpi
,HRT_PROFILES_B hpb
,HRT_PROFILES_TL hpt
,HRT_PROFILE_RELATIONS hpr
,HRT_PROFILE_EXTRA_INFO_VL hpeiv
,HR_ALL_POSITIONS_F hapf
where hpi.profile_id = hpb.profile_id
and hpb.profile_usage_code = 'M'
and hpi.profile_id = hpr.profile_id
and hpi.profile_id = hpt.profile_id
and hpi.profile_id = hpeiv.profile_id
and hapf.position_id = hpr.object_id
and trunc(sysdate) between hapf.effective_start_date and hapf.effective_end_Date
and hapf.position_code= '1099'
and hpt.language = 'US'
Query to extract only the profile data:
select hpb.profile_code
,hpt.description
,hpt.summary
,hpeiv.DESCRIPTION desc1
,hpeiv.RESPONSIBILITIES
,hpeiv.QUALIFICATIONS
,hikm.source_system_id
,hikm.source_system_owner
from HRT_PROFILES_B hpb
,HRT_PROFILES_TL hpt
,HRT_PROFILE_EXTRA_INFO_VL hpeiv
,HRC_INTEGRATION_KEY_MAP hikm
where hpeiv.profile_id = hpb.profile_id
and hpb.profile_usage_code = 'M'
and hpt.language = 'US'
and hpb.profile_code like '%TEST%'
and hikm.surrogate_id = hpeiv.PROFILE_EXTRA_INFO_ID
order by hpb.creation_date desc
Use the below query to get the details of Community in Learning:
SELECT asg.status,
asg.EVENT_TYPE,
asg.LEARNER_ID,
asg.EVENT_SUB_TYPE,
itm_tl.name learning_community_name,
(select full_name from per_person_names_f ppnf
where name_type ='GLOBAL'
and person_id = asg.LEARNER_ID
and trunc(sysdate) between effective_start_date and effective_end_date) member_name,
(select person_number from per_all_people_f papf
where person_id = asg.LEARNER_ID
and trunc(sysdate) between effective_start_date and effective_end_date) member_number
FROM wlf_assignment_records_f asg, wlf_learning_items_f itm,wlf_learning_items_f_tl itm_tl, WLF_LI_COMMUNITIES_F wlcf
WHERE TRUNC(SYSDATE) BETWEEN asg.effective_start_date AND asg.effective_end_date
and asg.status <> 'ORA_ASSN_REC_WITHDRAWN'
and itm.learning_item_id = asg.learning_item_id
and itm.learning_item_type in ('ORA_COMMUNITY')
and itm.learning_item_id =wlcf.learning_item_id
and itm.learning_item_id = itm_tl.learning_item_id
and itm_tl.language = 'US'
and TRUNC(SYSDATE) BETWEEN itm.effective_start_date AND itm.effective_end_date
and TRUNC(SYSDATE) BETWEEN itm_tl.effective_start_date AND itm_tl.effective_end_date
and itm_tl.name = 'Essential Workers'
ORDER by 5
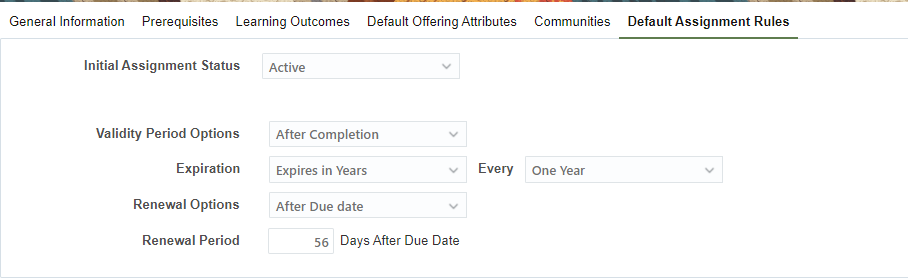
Default Assignment Rules like Validity Period, Expiration, Renewal Options, Renewal Period etc are maintained at the course level in Oracle Learning Cloud.
These details are stored in the backend table ‘WLF_ASSIGNMENT_RULES’.
The query from below post can be joined with WLF_ASSIGNMENT_RULES using ASSIGNMENT_RULE_ID column:
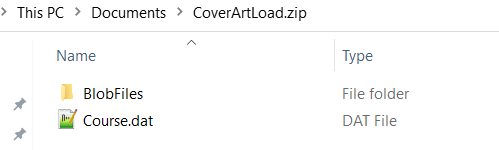
While creating the Courses in Oracle Learning Cloud, there is a capability to load CoverArt for each course. If no cover art is loaded, the learner is presented with a blue strip film.
HCM Data Loaders provides an option to bulk upload the CoverArt file for multiple courses at one go. All the cover art related files (jpg, jepg) should be included in BlobFiles folder and the name of the jpg/jpeg file should be provided in the dat file.
In the enhanced profiles (Profile V2), for bulk upload, one has to use TalentProfile.dat file as earlier. However while loading profile items against a profile, a new attribute SectionId should be provided. SectionId is based on the content item being used.
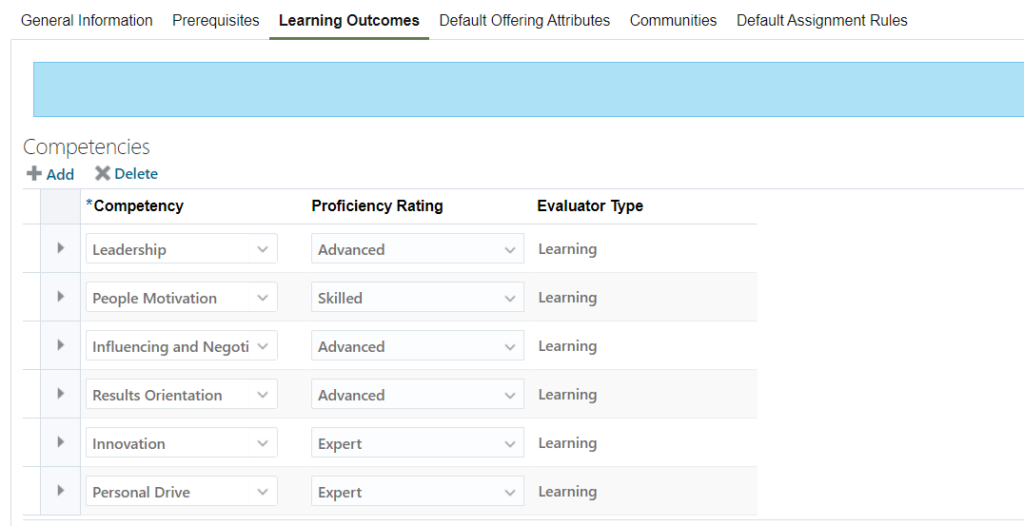
Oracle Learning Cloud supports to define learning outcomes against each course as shown in below fig:
For reporting and integration purposes, there is a need to extract the learning outcomes assigned against each course. Learning outcomes are stored as profile relationship against each course. Below query can be used to extract the asked data:
select wlifv.learning_item_number,
wlifv.name learning_item_name,
wlifv.learning_item_type,
wlifv.status,
wlifv.effective_start_date,
wlifv.effective_end_date,
hpi.content_type_id,
hpi.date_from,
hpi.date_to,
hpi.content_item_id competency_id,
hctt.content_type_name,
hcit.name content_item_name
from HRT_RELATION_CONFIG_B hrcb
,HRT_PROFILE_RELATIONS hpr
,HRT_CONTENT_TYPES_B hctb
,HRT_CONTENT_TYPES_TL hctt
,HRT_CONTENT_ITEMS_TL hcit
,HRT_PROFILE_ITEMS hpi
,HRT_PROFILES_B hpb
,WLF_LEARNING_ITEMS_F_VL wlifv
where hrcb.key_table_name = 'WLF_LEARNING_ITEMS_F_VL'
and hrcb.relation_code = 'LEARNING_ITEM'
and hrcb.relation_id = hpr.relation_id
and hpi.profile_id = hpr.profile_id
and hpi.content_type_id = hctb.content_type_id
and hctt.content_type_id = hctb.content_type_id
and hctb.context_name = 'COMPETENCY'
and hpi.profile_id = hpb.profile_id
and hpr.object_id = wlifv.learning_item_id
and hpb.profile_usage_code = 'L'
and hpi.content_item_id = hcit.content_item_id
and TRUNC(SYSDATE) BETWEEN wlifv.effective_start_date and wlifv.effective_end_date
and hctt.language = 'US'
and hcit.language = 'US'
ORDER BY 1
Lookups are commonly used across modules in SaaS. Sometimes, the number of lookups is so much that it takes lot of time and effort to create them manually in the application. Oracle SaaS supports bulk upload of both lookup types and lookup codes.
In this post, we will see how to make use of file based loader to load lookup types.
Prepare the lookup code file as given below:
LookupType|Meaning|Description|ModuleKey|ModuleType TXX_MASS_UPLOAD|Mass Upload Lookup Definition|Test Lookup created for demo purpose|HcmCommonHrCore|LBA TXX_MASS_UPLOAD_A|Mass Upload Lookup Def – A|Test Lookup created for demo purpose-A|HcmCommonHrCore|LBA
Out of above listed attributes, only the description is optional.
Module Key and module type both are required parameters. To know what value shall be passed, please check the below post:
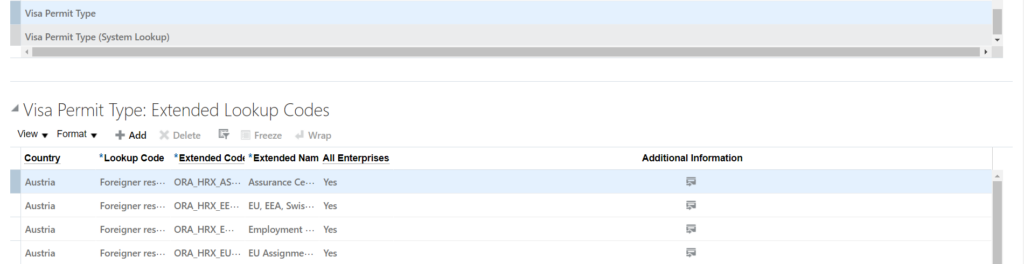
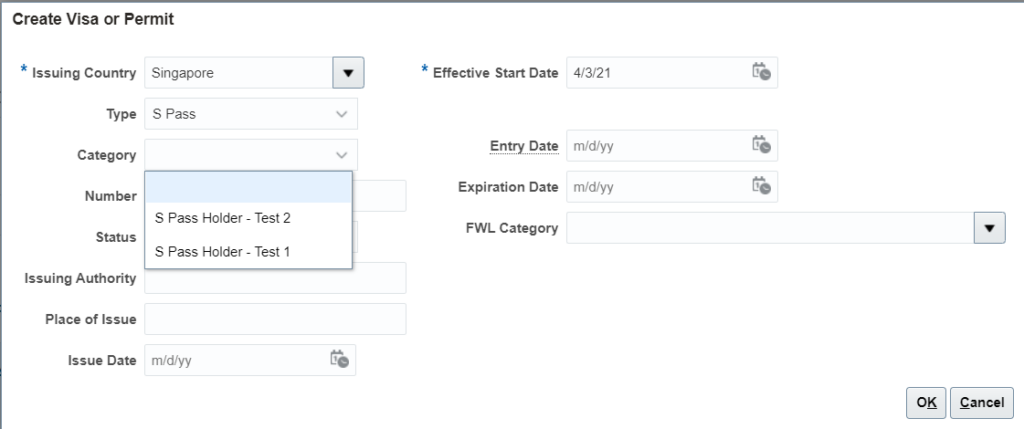
Oracle HCM makes use of extended lookups feature to support dependent lookup values. For example, while creating a VISA or Work Permit record for a Person for Singapore, the Category field is dependent upon Type of the pass chosen. The values of Category field are derived from Extended lookup.
Navigate to Setup and Maintenance -> Manage Extended Lookup codes -> Visa Permit Type
Now, let us take an example where we need to load 2 values for categories based on the lookup code S Pass.
Prepare the HDL file in below format:
METADATA|ExtendedLookupCode|ExtendedLookupCodeId|LookupType|LookupCode|LegislationCode|ExtendedLookupCode|ExtendedLookupCodeName|SourceSystemOwner|SourceSystemId MERGE|ExtendedLookupCode||PER_VISA_PERMIT_TYPE|SG_SP|SG|TEST_SP1|S Pass Holder – Test 1|HRC_SQLLOADER|TEST_1 MERGE|ExtendedLookupCode||PER_VISA_PERMIT_TYPE|SG_SP|SG|TEST_SP2|S Pass Holder – Test 2|HRC_SQLLOADER|TEST_2
zip the file and upload using HCM Data Loader from Data Exchange.
On successful load, the new values can be verified from either of following two places on the UI:
While defining Common Lookups or value sets, you need to provide module value. Each module has an associated module type, module key and product code associated with it. For example:
These details are stored in backed in a table – FND_APPL_TAXONOMY.
Use the below query to find module type, module key etc for a module:
select fat.MODULE_NAME
,fat.MODULE_TYPE
,fat.MODULE_KEY
,fat.PRODUCT_CODE
from FND_APPL_TAXONOMY fat
Lookups are used commonly to meet different requirements. Many a times, lookup values easily go past hundred values, in such case adding the values one by one into the lookup is very tedious and error prone job.
There is no HDL support to bulk upload the lookup values. However, a file based solution is available which is easy to use and quick.
We have already discussed on how to bulk upload lookup types in below post:
Follow the below steps to mass upload lookup values:
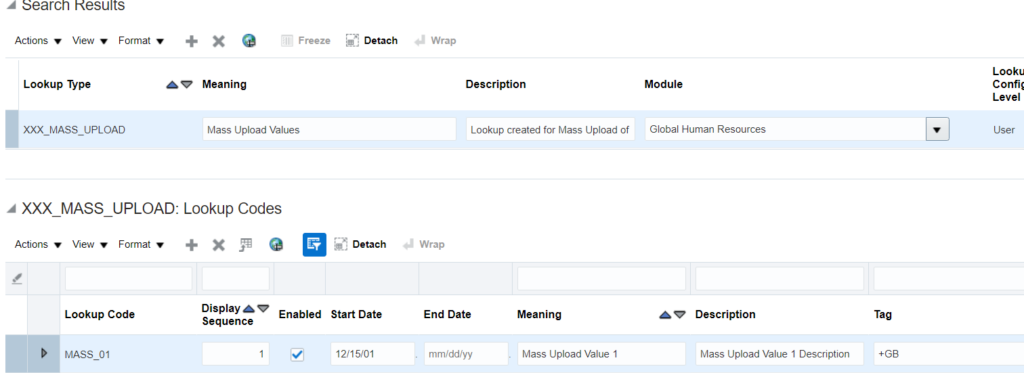
Create a custom lookup from UI:
[N] – Setup and Maintenance -> Search -> Manage Common Lookups
2. Click on Add New (+) under search results:
3. Provide the details and Click on Save:
4. Prepare the lookup values file in below format:
LookupType|LookupCode|DisplaySequence|EnabledFlag|StartDateActive|EndDateActive|Meaning|Description|Tag XXX_MASS_UPLOAD|MASS_01|1|Y|15/12/2001||Mass Upload Value 1|Mass Upload Value 1 Description|+GB
Below mentioned attributes in the above file are Mandatory:
-> LookupType
-> LookupCode
-> EnabledFlag
-> Meaning
Except these all other fields are optional.
Date Format for StartDateActive and EndDateActive attributes is DD/M/RRRR.
File should be pipe (|) delimited.
Save the file as csv.
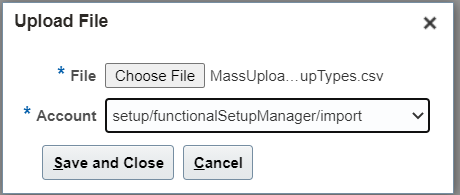
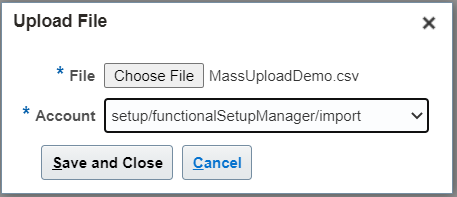
5. Once the file is ready, navigate to – Tools -> File Import and Export
6. Click on Add (+) and choose your file:
Select account as :-> setup/functionalSetupManger/import
Click on Save and Close.
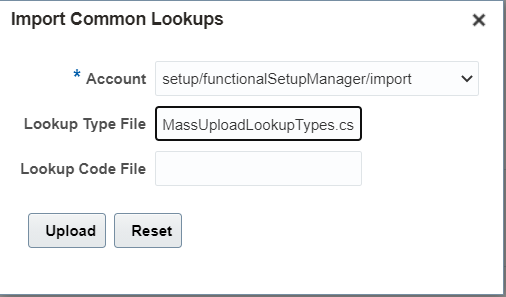
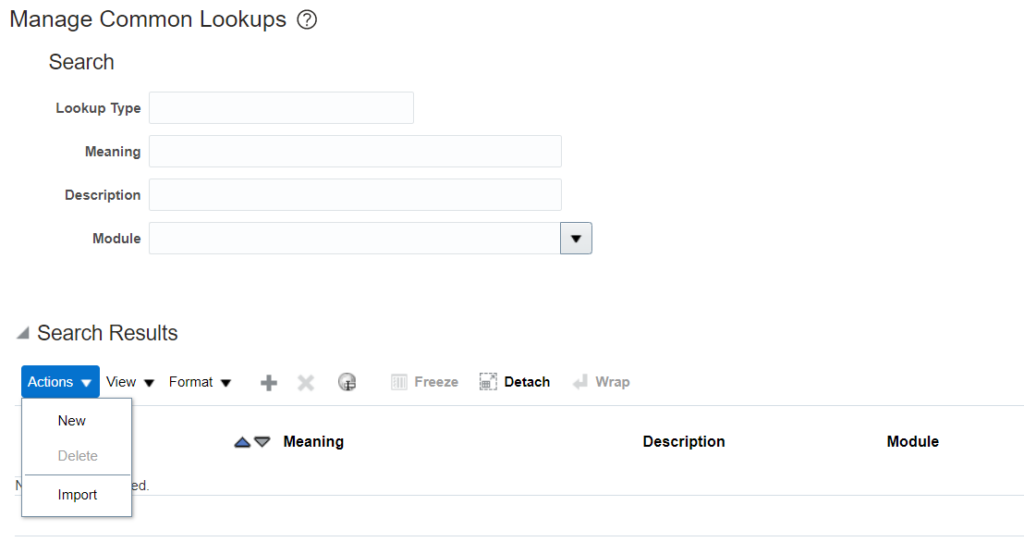
7. Navigate to Manage Common Lookups. Under Search Results click on Action and Import:
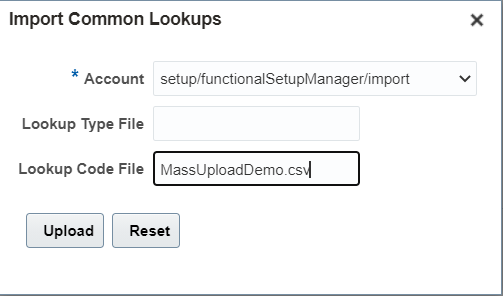
8. Select the account and give the file name as given in step 6 and Click on Upload button:
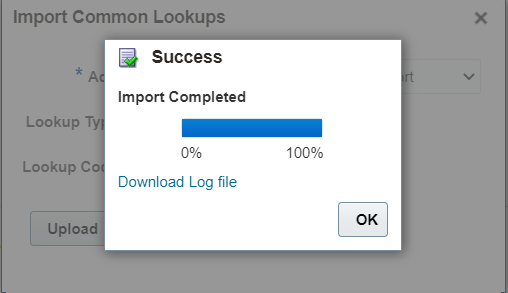
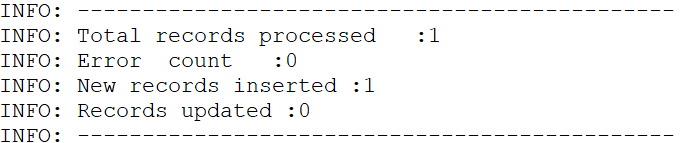
9. Monitor the import progress:
10. Once the import is complete, verify the uploaded values:
11. Results can be verified from Import file log as well:
Both Lookup types and lookup codes can be loaded in one shot as well. Prepare both the files simultaneously and follow the same steps as given above.
There is a common requirement to mask salary data post P2T refreshes. This should be done in order to hide the actual salaries information as salary is a very sensitive information.
Use the below query to generate data in HDL format in a test environment immediately after P2T refresh. The below query generate a random salary amount. Save the downloaded data in .dat file format and upload it back to the instance.
Select 'METADATA|Salary|AssignmentNumber|SalaryAmount|DateFrom|DateTo|SalaryBasisId|SalaryId' Header, 1 data_flow_order
from dual
UNION
SELECT 'MERGE|Salary'||'|'||
paam.assignment_number||'|'||
round(DBMS_RANDOM.VALUE (1,15000) , 2)||'|'||
TO_CHAR(cs.date_from,'RRRR/MM/DD', 'nls_date_language=American')||'|'||
TO_CHAR(cs.date_to,'RRRR/MM/DD', 'nls_date_language=American')||'|'||
cs.salary_basis_id||'|'||
cs.salary_id data_row,
2 data_flow_order
FROM cmp_salary cs,
per_all_assignments_m paam
WHERE cs.assignment_id= paam.assignment_id
AND trunc(sysdate) between paam.effective_start_date AND paam.effective_end_date
AND paam.assignment_type in ('E', 'C', 'P')
AND paam.assignment_number ='E788880'
ORDER BY data_flow_order