Often in Cloud HCM, we encounter situation(s) where we need to update some information at worker assignment, post worker creation as this information was not available at the time of hiring an worker. One such example could be Employee category. Let’s take a hypothetical example, employee category should be auto populated based on worker Job. As, there is no direct link between employee category and job, so it becomes a pain to manually search and put the correct employee category while hiring. So, in this case, the worker is hired with Job with no value for employee category.
A DFF is opened at Job level which store the corresponding employee category. So, in this case we design a solution which will:
- Read the worker job and then the corresponding employee category from Job.
- Generate the data for WorkTerms and Assignments METADATA in HCM Data Loader Format.
- HCM Extract to consume the data and trigger HDL Import and Load Process.
- Schedule HCM Extract to run daily or depending upon the requirement.
Once, HCM Extract is run, employee category will populated automatically.
Steps to design the integration:
- Extract the Workterms and assignment data for all workers where the job is populated and employee category is NULL.
- Create a BIP publisher report to organize the data extracted in Step 1 in HCM Data Loader format. Copy the Global Reports Data Model (from path /Shared Folders/Human Capital Management/Payroll/Data Models/globalReportsDataModel) to a folder in /Shared Folders/Custom/HR. This folder can be anything as per your nomenclature specifications.
- Add a new data set in the globalReportsDataModel and paste your query in the new data set.
- Check below post on sample query to extract the data in HCM Data Loader format: https://fusionhcmconsulting.com/2021/01/hdl-updating-an-attribute-on-assignment/
- Create an etext template (sample RTF template is available to above link) and a report based on above data model.
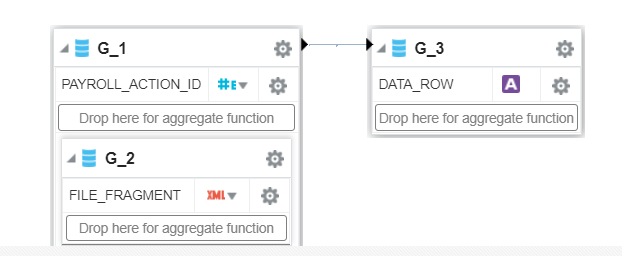
- Global Data Model will look like (G_3 is new data set):-
Steps to create HCM Extract:
You can import the below sample extract in your environment:
- Download the above file. Change the extension to xml.
- Open the xml file with Notepad or Notepad++ and remove first two rows (these rows were added to make sure the file is uploaded here).
- Navigate to My Client Groups -> Data Exchange -> HCM Extracts -> Extract Definitions:
- Click on Import to import the xml file
- Provide an Extract name. Uncheck the Changes Only checkbox and click on Ok:
- Once the extract Import is complete, Click on pencil icon to edit:
- Click on ‘Extract Delivery Option’ in navigation Tree on left side. And on the right side, Under ‘Extract Delivery Options’ click on edit to update the path of your report as created earlier. It should like – /Custom/HR/AssignmentUpdateRPT.xdo
- Make sure default value for parameter Auto Load is set “Y”.
- Save the details. Click on Extract Execution Tree next and Click All Formula:
- Once the formulas are complied, then click on Submit button.
The next step is to refine the extract in order to Submit the Import and Load process:
- Navigate to My Client Groups -> Data Exchange -> HCM Extracts -> Refine Extracts. Search the extract and click on edit.
- Select and Add – Initiate HCM Data Loader process
- Click on Go Task for “Initiate HCM Data Loader” and Click Edit for “ Data Loader Archive Action” and add the relevant parameters:
Parameter Basis – Bind to Flow Task
Basis Value – XX Assignment Update Integration, Submit , Payroll Process

- Click Edit for “Data Loader Configurations” add relevant parameters
Parameter Basis – Constant Bind
Basis Value -ImportMaximumErrors=100,LoadMaximumErrors=100,LoadConcurrentThreads=8,LoadGroupSize=100
- Task sequence should look as follows:
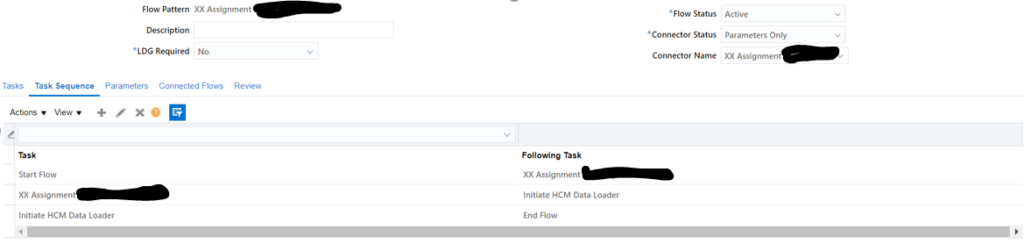
- Go to Review and click on Submit.
Your extract is now ready for submission. You can submit the extract and test it.