Oracle provides a process Purge Person Data in Test Environments to remove Person/Contact/Worker records from a test environment of Oracle HCM. Please note that HDL for core worker object doesn’t support DELETE, so there is no other option to purge the Person/Contact/Worker information from Oracle HCM once a record is created. In this case, Purge Person Data in Test Environments is definitely a useful utility which helps to purge person related data from a test environment.
This process can’t be run in Oracle HCM Production.
Before 21D, the process required an additional step to get a key to enable to process in Test environments but from 21D onwards the process is enabled by default in all test environments.
You can find more details related to this process on below link:
https://docs.oracle.com/en/cloud/saas/human-resources/22c/fahdl/enable-the-purge-person-data-in-test-environments-process.html#s20065832
Below is the list of tables which gets purged once the process completes:
https://docs.oracle.com/en/cloud/saas/human-resources/22c/fahdl/tables-purged-by-the-purge-person-data-in-test-environments.html#s20065826
To run the process:
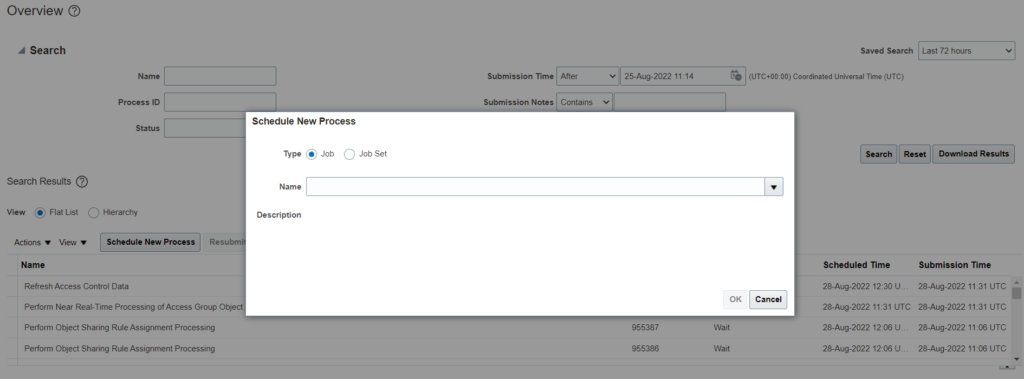
- Navigate to Tools -> Scheduled Process
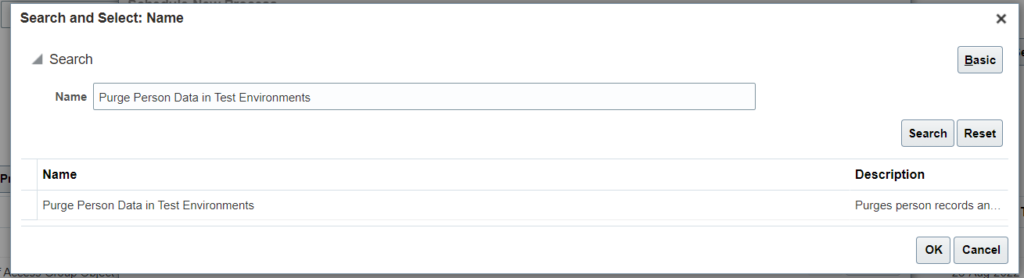
- Click on schedule new process –> Search for Purge Person Data in Test Environments
- Supply the parameters
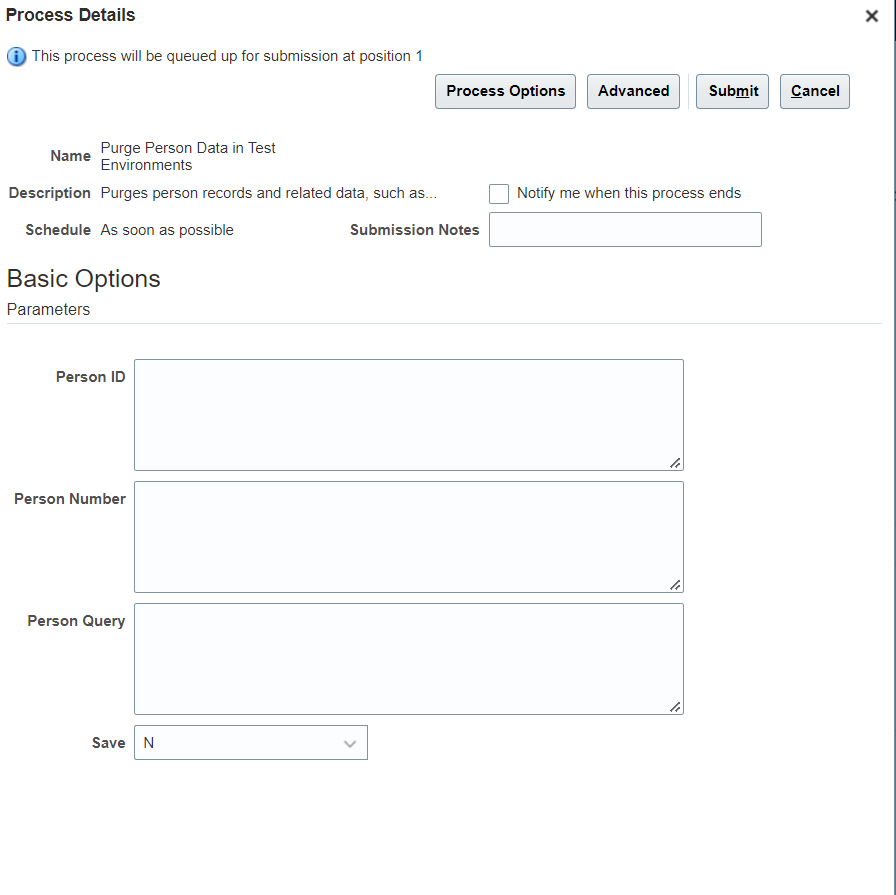 Make sure Save is set to Y to purge the records from DB.
Make sure Save is set to Y to purge the records from DB.
Sample Person SQL’s:
To remove only Contact Person records:
SELECT DISTINCT papf.person_id FROM per_all_people_f papf WHERE 1=1 AND NOT EXISTS (SELECT 1 FROM per_periods_of_service ppos where ppos.person_id = papf.person_id)
To remove all person records:
SELECT DISTINCT papf.person_id FROM per_all_people_f papf
Use below SQL to monitor the progress of entries in each table:
SELECT a.*
FROM
(
SELECT 'ANC_PER_ABS_ENTRIES' table_name, count(*) rowcount FROM ANC_PER_ABS_ENTRIES
UNION
SELECT 'ANC_PER_ABS_ENTRY_DTLS' table_name, count(*) rowcount FROM ANC_PER_ABS_ENTRY_DTLS
UNION
SELECT 'ANC_PER_ABS_MATERNITY' table_name, count(*) rowcount FROM ANC_PER_ABS_MATERNITY
UNION
SELECT 'ANC_PER_PLAN_ENROLLMENT' table_name, count(*) rowcount FROM ANC_PER_PLAN_ENROLLMENT
UNION
SELECT 'ANC_PER_ABS_PLAN_ENTRIES' table_name, count(*) rowcount FROM ANC_PER_ABS_PLAN_ENTRIES
UNION
SELECT 'ANC_PER_ACCRUAL_ENTRIES' table_name, count(*) rowcount FROM ANC_PER_ACCRUAL_ENTRIES
UNION
SELECT 'ANC_PER_ACRL_ENTRY_DTLS' table_name, count(*) rowcount FROM ANC_PER_ACRL_ENTRY_DTLS
UNION
SELECT 'CMP_SALARY' table_name, count(*) rowcount FROM CMP_SALARY
UNION
SELECT 'PAY_ASSIGNED_PAYROLLS_DN' table_name, count(*) rowcount FROM PAY_ASSIGNED_PAYROLLS_DN
UNION
SELECT 'PAY_ASSIGNED_PAYROLLS_F' table_name, count(*) rowcount FROM PAY_ASSIGNED_PAYROLLS_F
UNION
SELECT 'PER_ADDRESSES_F' table_name, count(*) rowcount FROM PER_ADDRESSES_F
UNION
SELECT 'PER_ALL_ASSIGNMENTS_M' table_name, count(*) rowcount FROM PER_ALL_ASSIGNMENTS_M
UNION
SELECT 'PER_ALL_PEOPLE_F' table_name, count(*) rowcount FROM PER_ALL_PEOPLE_F
UNION
SELECT 'PER_ASSIGN_WORK_MEASURES_F' table_name, count(*) rowcount FROM PER_ASSIGN_WORK_MEASURES_F
UNION
SELECT 'PER_CITIZENSHIPS' table_name, count(*) rowcount FROM PER_CITIZENSHIPS
UNION
SELECT 'PER_DRIVERS_LICENSES' table_name, count(*) rowcount FROM PER_DRIVERS_LICENSES
UNION
SELECT 'PER_EMAIL_ADDRESSES' table_name, count(*) rowcount FROM PER_EMAIL_ADDRESSES
UNION
SELECT 'PER_ETHNICITIES' table_name, count(*) rowcount FROM PER_ETHNICITIES
UNION
SELECT 'PER_NATIONAL_IDENTIFIERS' table_name, count(*) rowcount FROM PER_NATIONAL_IDENTIFIERS
UNION
SELECT 'PER_PASSPORTS' table_name, count(*) rowcount FROM PER_PASSPORTS
UNION
SELECT 'PER_PEOPLE_LEGISLATIVE_F' table_name, count(*) rowcount FROM PER_PEOPLE_LEGISLATIVE_F
UNION
SELECT 'PER_PERIODS_OF_SERVICE' table_name, count(*) rowcount FROM PER_PERIODS_OF_SERVICE
UNION
SELECT 'PER_PERSON_ADDR_USAGES_F' table_name, count(*) rowcount FROM PER_PERSON_ADDR_USAGES_F
UNION
SELECT 'PER_PERSON_NAMES_F' table_name, count(*) rowcount FROM PER_PERSON_NAMES_F
UNION
SELECT 'PER_PERSON_TYPE_USAGES_M' table_name, count(*) rowcount FROM PER_PERSON_TYPE_USAGES_M
UNION
SELECT 'PER_PERSONS' table_name, count(*) rowcount FROM PER_PERSONS
UNION
SELECT 'PER_PHONES' table_name, count(*) rowcount FROM PER_PHONES
UNION
SELECT 'PER_RELIGIONS' table_name, count(*) rowcount FROM PER_RELIGIONS
UNION
SELECT 'PER_VISAS_PERMITS_F' table_name, count(*) rowcount FROM PER_VISAS_PERMITS_F
UNION
SELECT 'PAY_ELEMENT_ENTRIES_F' table_name, count(*) rowcount FROM PAY_ELEMENT_ENTRIES_F
UNION
SELECT 'PAY_ELEMENT_ENTRY_VALUES_F' table_name, count(*) rowcount FROM PAY_ELEMENT_ENTRY_VALUES_F
UNION
SELECT 'PER_WORKING_HOUR_PATTERNS_F' table_name, count(*) rowcount FROM PER_WORKING_HOUR_PATTERNS_F
UNION
SELECT 'PER_ASSIGNMENT_EXTRA_INFO_M' table_name, count(*) rowcount FROM PER_ASSIGNMENT_EXTRA_INFO_M
UNION
SELECT 'PER_ASSIGNMENT_SUPERVISORS_F' table_name, count(*) rowcount FROM PER_ASSIGNMENT_SUPERVISORS_F
UNION
SELECT 'PER_PEOPLE_EXTRA_INFO_F' table_name, count(*) rowcount FROM PER_PEOPLE_EXTRA_INFO_F
UNION
SELECT 'HR_DOCUMENTS_OF_RECORD ' table_name, count(*) rowcount FROM HR_DOCUMENTS_OF_RECORD
UNION
SELECT 'PER_CONTACT_RELATIONSHIPS ' table_name, count(*) rowcount FROM PER_CONTACT_RELATIONSHIPS
) a
where
a.rowcount <> 0
You can add/remove more tables based on data in your environment.
Stats:
Normally the process takes around 5-6 hrs for 16-17K employees. Performance depends upon environment sizing as well among other factors.