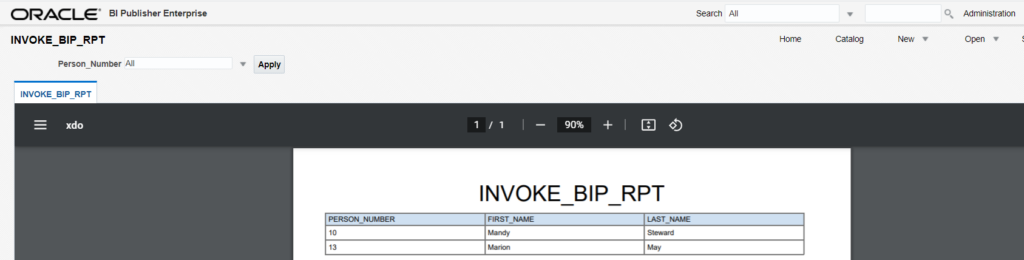
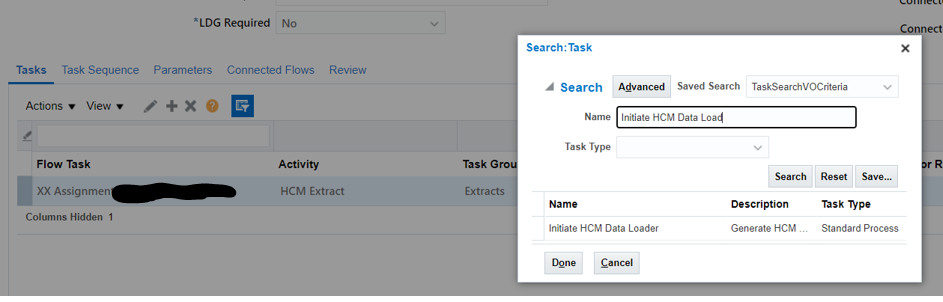
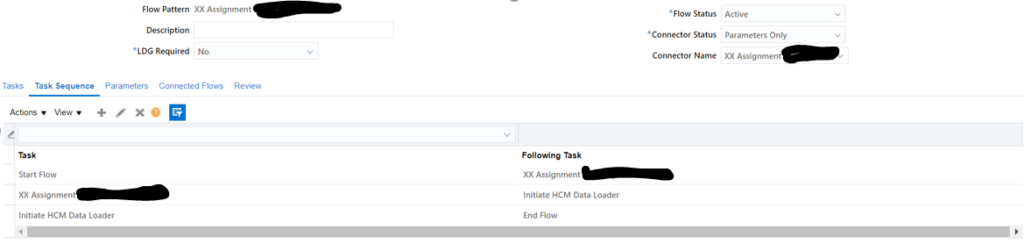
HDL – Sample File to DELETE documents of Record
Use the below query to extract document of record data which should be deleted. You can add additional filters by adding person numbers.
select 'DELETE' "METADATA"
,'DocumentsOfRecord' "DocumentsOfRecord"
,hdor.documents_of_record_id "DocumentsOfRecordId"
,hdor.document_type_id "DocumentTypeId"
,hdor.document_code "DocumentCode"
,hdor.document_name "DocumentName"
,hdor.document_number "DocumentNumber"
,hikm.source_system_owner "SourceSystemOwner"
,hikm.source_system_id "SourceSystemId"
from HR_DOCUMENTS_OF_RECORD hdor
,HRC_INTEGRATION_KEY_MAP hikm
where hdor.documents_of_record_id = hikm.surrogate_id
and hdor.documents_of_record_id = 300000217125443Query for Person Number and Document Type:
select DISTINCT 'DELETE' "METADATA"
,'DocumentsOfRecord' "DocumentsOfRecord"
,hdor.documents_of_record_id "DocumentsOfRecordId"
,hdor.document_type_id "DocumentTypeId"
,hdor.document_code "DocumentCode"
,hdor.document_name "DocumentName"
,hdor.document_number "DocumentNumber"
,hikm.source_system_owner "SourceSystemOwner"
,hikm.source_system_id "SourceSystemId"
from HR_DOCUMENTS_OF_RECORD hdor
,HRC_INTEGRATION_KEY_MAP hikm
,PER_ALL_PEOPLE_F papf
,HR_DOCUMENT_TYPES_TL hdtt
where hdor.documents_of_record_id = hikm.surrogate_id
--and hdor.documents_of_record_id = 300000217125443
and hdor.person_id = papf.person_id
and TRUNC(SYSDATE) BETWEEN papf.effective_start_date AND papf.effective_end_date
and hdor.document_type_id = hdtt.document_type_id
and hdtt.language = 'US'
and hdtt.DOCUMENT_TYPE = 'Test Doc'
and papf.person_number IN ('12','23')Sample HDL File:
METADATA|DocumentsOfRecord|DocumentsOfRecordId|DocumentTypeId|DocumentCode|DocumentName|DocumentNumber|SourceSystemOwner|SourceSystemId
DELETE|DocumentsOfRecord|300000217125443|300000217168555|TMAD_001|Multiple Attachments||HRC_SQLLOADER|HRC_SQLLOADER_101_TMAD_001