With the security concerns regarding access to Oracle HCM applications, I have seen many customers asking for a way to restrict access to a particular DEV/TEST environment having unmasked data. One option in such scenario’s is to keep only the admin user accounts active in the particular environment and deactivate all other user accounts. This way, the user roles data is kept intact and access is restricted to only a set of limited users.
Let us now understand, the kind of users which can exist in Fusion HCM environment. There can be system users (seeded), service accounts, worker accounts (users tied to a person), standalone user accounts (for vendors/ SI partners). So, it is really important to filter the right set of user accounts which should be deactivated. Also, the method of deactivation can vary depending upon the type of user.
Bulk deactivation of users can be performed using either HDL or by using SCIM REST API. While HDL is bulk data upload tool but it has its own set of limitations. HDL can’t be used to deactivate standalone users i.e. the users which don’t have an associated person record. To deactivate standalone users, REST API should be used.
I will discuss both the approaches in details. Let us first find a way to store the admin user accounts which should remain active. My preferred way of doing this is to create a Common Lookup and add the details (user names) in this lookup. This is because lookup values can be updated easily using a spreadsheet loader.
Below is the sample lookup (XX_ACTIVE_USER_ACCOUNTS) which I created to store the admin user names:

Next step is to add the user accounts in the meaning attribute:
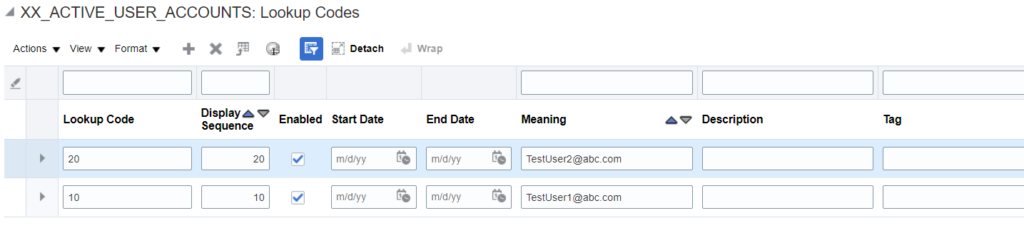
Two user accounts – TestUser1@abc.com and TestUser2@abc.com have been added. The next steps will be to filter these record from the deactivation steps.
Let us now discuss the first approach which is to deactive user accounts using HDL. Below SQL query can be used to get a list of all required active user accounts in User.dat HDL format:
SELECT 'METADATA|User|UserId|Suspended' datarow
,1 seq
FROM DUAl
UNION
SELECT 'MERGE|User|'
|| pu.user_id
|| '|Y' datarow
,2 seq
FROM per_users pu
WHERE pu.person_id IS NOT NULL
AND pu.created_by NOT IN ('anonymous')
AND pu.username NOT LIKE 'FUSION%APPS%'
AND pu.username NOT IN ('AIACS_AIAPPS_LHR_STAGE_APPID','FAAdmin','FAWService','FAWService_APPID','FIISUSER','HCMSI-98f0f163a79a46c58fa4572e41fac8ed_scim_client_APPID','IDROUser','IDRWUser', 'OCLOUD9_osn_APPID','PSCR_PROXY_USER','PUBLIC','app_monitor1','app_monitor', 'em_monitoring2','fa_monitor','faoperator','oamAdminUser','puds.pscr.anonymous.user','weblogic_idm','anonymous'
)
AND pu.suspended = 'N'
AND lower(pu.username) NOT IN (SELECT lower(flv.meaning)
FROM fnd_lookup_values flv
WHERE flv.lookup_type = 'XX_ACTIVE_USER_ACCOUNTS'
AND flv.language = 'US'
AND flv.enabled_flag = 'Y'
)
ORDER BY seq
So, the above query will return only those active user accounts which are attached to a person record and don’t exist in the custom lookup XX_ACTIVE_USER_ACCOUNTS.
**Suspended Flag in PER_USERS table indicate if the user is active (N) or inactive (Y).
Next step is to create a BIP data model and a report and save the output data in excel format. From excel, copy the data in a Notepad and save the file as User.dat.
Sample Output in excel format:
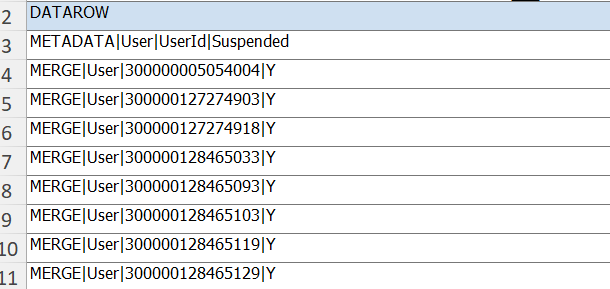
Copy the data except for “DATAROW” and paste it in a Notepad. Save the file as User.dat:

zip the User.dat file and upload it in HCM using Data Exchange -> Import and Load.
Once the load is successful, please run – ‘Send Pending LDAP Requests’ ESS job. This should deactivate all the extracted users.
You can run quick queries on per_users to make sure that the user accounts have been deactivated.
Second approach is to use SCIM REST API to bulk deactivate user accounts. I recommend to use this approach only for those users where no person record is attached to the user account.
Please check below MOS note for details on the step by step instructions on SCIM REST API:
Fusion Security: Using SCIM REST API (Doc ID 2346455.1)
Please note that in order to run this REST API, the user should have – IT Security Manager role.
Sample url to bulk deactivate users :-
https://fa-abcdef-dev-saasfaprod1.fa.ocs.oraclecloud.com/hcmRestApi/scim/Bulk
Sample Payload:
{
"Operations":[
{
"method":"PATCH",
"path":"/Users/0453A72EE08D419BE0631078680AA831",
"bulkId":"100000001",
"data":{
"schemas":[
"urn:scim:schemas:core:2.0:User"
],
"active":false
}
},
{
"method":"PATCH",
"path":"/Users/0453A72EE08D419BE0631078612AA832",
"bulkId":"100000001",
"data":{
"schemas":[
"urn:scim:schemas:core:2.0:User"
],
"active":false
}
}
]
}
Please note (taken from above Oracle note):
The bulkId attribute value should be set to UNIQUE value, while creating user accounts in BULK. This is required as per IETF SCIM Specifications while creating new resources using POST method. You may use a common value for the bulkId attribute while using PATCH, DELETE, PUT methods in a Bulk operation.
The main challenge with this approach is to get the correct JSON Payload for multiple users from system. I have created a BIP report for this which will generate the output data in required JSON format. Below is the sample code:
SELECT '{
"Operations":['
data_row, 1 seq
FROM DUAL
UNION
SELECT
'{
"method":"PATCH",
"path":"/Users/'
||pu.user_guid||
'",
"bulkId":"1000000000001",
"data":{
"schemas":[
"urn:scim:schemas:core:2.0:User"
],
"active":false
}
},' data_row, 2 seq
FROM per_users pu
WHERE pu.person_id IS NOT NULL
AND pu.created_by NOT IN ('anonymous')
AND pu.username NOT LIKE 'FUSION%APPS%'
AND pu.username NOT IN ('AIACS_AIAPPS_LHR_STAGE_APPID','FAAdmin','FAWService','FAWService_APPID','FIISUSER',
'HCMSI-98f0f163a79a46c58fa4572e41fac8ed_scim_client_APPID','IDROUser','IDRWUser',
'OCLOUD9_osn_APPID','PSCR_PROXY_USER','PUBLIC','app_monitor1','app_monitor',
'em_monitoring2','fa_monitor','faoperator','oamAdminUser','puds.pscr.anonymous.user',
'weblogic_idm','anonymous'
)
AND pu.suspended = 'N'
AND lower(pu.username) NOT IN (SELECT lower(flv.meaning)
FROM fnd_lookup_values flv
WHERE flv.lookup_type = 'XX_ACTIVE_USER_ACCOUNTS'
AND flv.language = 'US'
AND flv.enabled_flag = 'Y'
)
UNION
SELECT '
]
}' data_row, 3 seq
FROM dual
ORDER BY seq
You can create a BIP data model and report to get data from this query. Extract the data in excel format and copy it to a notepad. Then you need to remove the highlighted comma in order for this JSON payload to work.
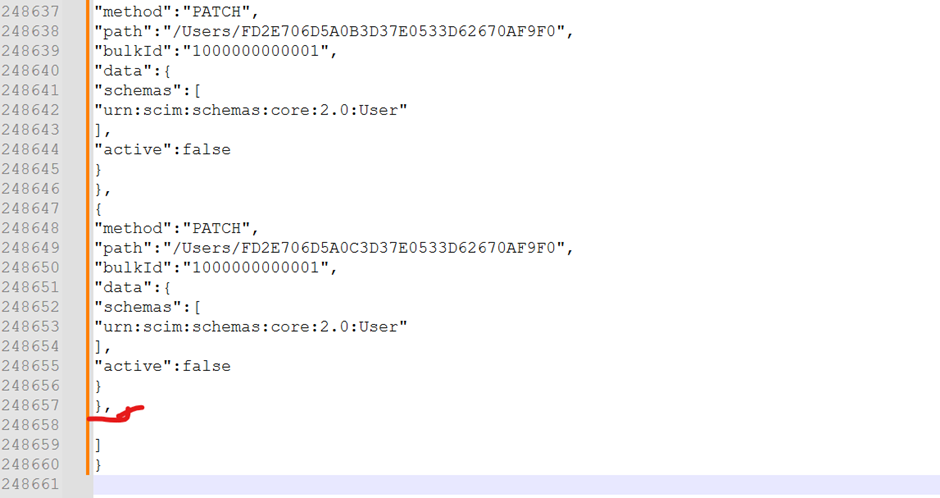
You can use SOAP UI/Postman to run the REST API and provide the output from Notepad as JSON input. Once the API runs successfully, the suspended flag will get changed to Y in per_users table.